모던 자바 인 액션 7장에서는 스트림 병렬 처리에 대해서 소개하고 있다.
스트림으로 얼마나 쉽게 병렬로 처리하는지 포크/조인 프레임워크와 어떤 관계가 있는지 살펴본다.
7.1 병렬 스트림
컬렉션에 parallelStream 을 호출하면 병렬 스트림(parallel stream) 을 생성할 수 있다.
병렬 스트림을 이용하면 각 멀티코어 프로세서가 일을 처리하도록 할당할 수 있다.
parallel메서드를 호출하면 병렬 스트림으로 변환 (병렬로 수행한다는 불리언 플래그가 설정)- 반대로
sequential호출하면 순차 스트림으로 변환 - 상황에 따라 병렬화를 하는 것보다 적절한 자료구조를 선택하는 것이 중요(오토 박싱, 언박싱 등의 오버헤드 주의)
- 코어간 데이터 전송 시간보다 오래 걸리는 작업만 병렬로 수행하는 것이 바람직
병렬 스트림 효과적으로 사용하기
- 확신이 서지 않으면 직접 측정하라
- 언제나 병렬 스트림이 빠르지 않기 때문에, 어느 것이 좋은지 모르겠다면 직접 성능을 측정하는 것이 바람직하다.
- 박싱을 주의하라
- 자동 박싱과 언박싱은 성능을 크게 저하시킨다.
- 가능하면 기본형 특화 스트림을 이용하자
- 순차 스트림보다 병렬 스트림에서 성능이 떨어지는 연산이 있다
list,findFirst처럼 요소의 순서에 의존하는 연산은 병렬 스트림에서 비용이 크다.- 요소의 순서가 상관 없다면
unordered로 비정렬된 스트림을 얻고limit을 호출하는 것이 효율적이다.
- 스트림에서 수행하는 전체 파이프라인 연산 비용을 고려하라
- 전체 처리 비용이 N(요소 수) * Q(처리 비용) 일 때, Q 가 높아지면 병렬 스트림으로 성능을 개선할 수 있는 가능성이 있다.
- 소량의 데이터에서는 병렬 스트림이 도움 되지 않는다.
- 병렬화 과정에서 생기는 부가 비용이 클 수 있다.
- 자료구조가 적절한지 확인하라.
- 분할할 때
LinkedList은 모든 요소 탐색,ArrayList은 탐색하지 않고도 가능하기 때문에ArrayList이 더 효율적
- 분할할 때
- 중간 연산이 스트림의 특성을 어떻게 바꾸는지에 따라 분해 과정의 성능이 달라질 수 있음
SIZED스트림은 정확히 같은 크기의 스트림으로 분할할 수 있어서 효율적으로 병렬 처리 가능- 필터 연산이 존재하면 길이를 예측할 수 없어서 효과적으로 병렬 처리가 가능한지 알 수 없음
- 최종 연산의 병합 과정 비용을 살펴보라
- 병합 과정의 비용이 비싸다면 오히려 병렬 스트림으로 얻은 이익이 상쇄될 수 있음
7.2 포크/조인 프레임워크
포크/조인 프레임워크는 병렬화할 수 있는 작업을 재귀적으로 작업을 분할하고 각 결과를 합쳐서 전체 결과를 가져오도록 설계되었다.
스레드 풀을 이용하려면 RecursiveTask<R>, RecursiveAction(결과가 없는 경우) 을 상속받아 다음 추상 메서드를 구현해야 한다.
protected abstract R compute();
다음은 포크/조인 프레임워크를 이용해 병렬 합계를 수행하는 예시 코드다.
일반적으로 ForkJoinPool 은 애플리케이션에서 한 번만 인스턴스화해서 싱글턴으로 저장해서 재사용한다.
// RecursiveTask 를 상속받아 포크/조인 프레임워크에서 사용할 태스크 생성
public class ForkJoinSumCalculator extends java.util.concurrent.RecursiveTask<Long> {
private final long[] numbers;
private final int start;
private final int end;
public static final long THRESHOLD = 10_000;
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
// ForkJoinPool 에 전달되면 실행되는 메서드
@Override
protected Long compute() {
int length = end - start;
if (length <= THRESHOLD) {
return computeSequentially(); // 기준값 이하라면 결과 계산
}
// 배열의 절반씩 더하도록 서브태스크들 생성
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length/2);
leftTask.fork(); // ForkJoinPool 의 다른 스레드로 생성한 태스크를 비동기로 실행
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length/2, end);
Long rightResult = rightTask.compute(); // 두번째 서브태스크를 동기 실행, 분할이 일어날 수 있음
Long rightResult = leftTask.join(); // 첫번째 서브태스크의 결과를 가져오거나 대기
return leftResult + rightResult;
}
private long computeSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
}
// 사용 코드
long[] numbers = LongStream.rangeClosed(1, n).toArrray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
new ForkJoinPool().invoke(task);
포크/조인 프레임워크 제대로 사용하는 방법
- 두 서브태스크가 모두 시작된 다음에
join을 호출해야 한다.- 각 서브태스크가 다른 태스크를 기다리게 된다면 기존보다 느리고 복잡해진다.
RecursiveTask내에서ForkJoinPool의invoke을 호출하면 안된다.- 순차 코드에서 병렬 계산을 시작할 때만
invoke사용
- 순차 코드에서 병렬 계산을 시작할 때만
- 서브태스크에
fork메서드를 호출해서ForkJoinPool의 일정을 조절할 수 있다.- 모두
fork호출하는 것보다 한쪽은compute를 호출하는 것이 효율적이다. (같은 스레드를 재사용하므로 오버헤드를 피할 수 있음)
- 모두
- 포크/조인 프레임워크를 이용하는 병렬 계산은 디버깅하기 어렵다.
- 다른 스레드에서
compute를 호출하므로 스택 트레이스가 도움되지 않음
- 다른 스레드에서
- 포크/조인 프레임워크를 사용하는 것이 반드시 빠른 것은 아니다.
- 여러 번 프로그램을 실행하여 성능을 측정해봐야 한다.
작업 훔치기
- 기준을 찾기 위해서는 기준값을 바꿔보면서 실행하는 것이 가장 좋은 방법이다.
- 코어 개수와 상관없이 태스크를 적절한 크기로 분할하여 포킹하는 것이 바람직하다.
- 코어 개수만큼 병렬화하면 다양한 이유(비효율적인 분할 기법, 디스크 접근 속도 저하, 외부 서비스 협력 과정 등)로 지연이 생길 수 있다.
위와 같은 문제들을 포크/조인 프레임워크에서는 작업 훔치기(work stealing)라는 기법으로 해결한다.
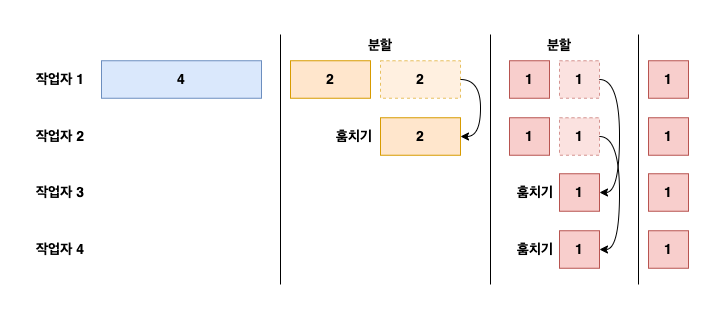
- 이 기법으로
ForkJoinPool모든 스레드를 공정하게 분할한다. - 작업이 끝나도 유휴 상태로 바뀌지 않고 큐의 헤드에서 다른 태스크를 가져와 처리
7.3 Spliterator 인터페이스
Spliterator 는 자바 8에서 제공하는 새로운 인터페이스로 병렬 작업에 특화되어 있다.
publid interface Spliterator<T> {
// 탐색해야 할 요소가 남아있으면 참
boolean tryAdvance(Consumer<? super T> action);
// 일부 요소를 분할해서 두번째 Spliterator 를 생성하는 메서드
// null 이 반활 될 때까지 새로운 Spliterator 생성
Spliterator<T> trySplit();
// 메서드로 탐색해야 할 요소 수
long estimateSize();
// Spliterator 특성 집합을 포함하는 int 반환
int characteristics();
}
Spliterator 특성
- ORDERED
- 리스트 처럼 정해진 순서가 있음
- DISTINCT
- x, y 두 요소를 방문했을 때
x.equals(y) == false
- x, y 두 요소를 방문했을 때
- SORTED
- 탐색된 요소는 정렬 순서를 따름
- SIZED
- 크기가 알려진 소스를 생성하여
estimateSize은 정확한 값을 반환
- 크기가 알려진 소스를 생성하여
- NON-NULL
- 탐색하는 모든 요소는 null 이 아님
- IMMUTABLE
Spliterator의 소스는 불변 (추가, 삭제, 수정 불가)
- CONCURRENT
- 동기화 없이 여러 스레드에서 동시에 수정 가능
- SUBSIZED
- 분할되는 모든
Spliterator은 SIZED 특성을 가짐
- 분할되는 모든
단어 수 계산 예시
class WordCounterSpliterator implements Spliterator<Character> {
private final String string;
private int currentChar = 0;
public WordCounterSpliterator(String string) {
this.string = string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
action.accept(string.charAt(currentChar++)); // 현재 문자 소비
return currentChar < string.length(); // 소비할 문자 남아있는지 확인
}
// 반복될 자료구조를 분할하는 메서드
@Override
public Spliterator<Character> trySplit() {
int currentSize = string.length() - currentChar;
if (currentSize < 10) {
return null; // 순차 처리 가능할 정도로 작아졌으므로 null 반환
}
for (int splitPos = currentSize / 2 + currentChar; splitPos < string.length(); splitPos++) {
if(Character.isWhitespace(string.charAt(splitPos))) {
Spliterator<Character> spliterator = new WordCounterSpliterator(string.substring(currentChar, splitPos));
currentChar = splitPos;
return spliterator;
}
}
return null;
}
@Override
public long estimateSize() {
return string.length() - currentChar;
}
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NON_NULL + IMMUTABLE;
}
}
Spliterator<Character> spliterator = new WordCounterSpliterator(SENTENCE);
Stream<Character> stream = StreamSupport.stream(spliterator, true); // 두 번째 불리언 인수는 병렬 스트림 생성 여부