SQL 을 효과적으로 활용하기 위해 SQL AntiPattern 의 내용을 정리한다.
1부에서는 데이터베이스 테이블과 컬럼, 관계를 계획하는 방법에 대해 알아본다.
2장 무단횡단: 다중 값 속성 저장
다대다 관계를 위해 교차 테이블 생성을 피하기 위해 쉼표(,)로 구분된 목록을 사용한다.
이러한 안티패턴을 책에서는 ‘무단횡단’ 또는 ‘교차로’ 로 표현했다.
안티패턴: 쉼표로 구분된 목록에 저장
product 테이블의 account_id 컬럼을 VARCHAR 로 선언하고 쉼표로 구분해 나열하는 방법
(ex. ‘12,34’)
- 특정 계정에 대한 상품을 찾기 위해서는 패턴 매칭 필요
- ex)
REGEXP,LIKE…
- ex)
- 계정을 조회하기 위해서는 어려운 조인, 많은 비용 발생
- 인덱스 활용 불가
- 두 테이블의 카테시안 곱 생성하여 평가
- 제품 별 계정 정보를 집계하기 위해서는
COUNT,SUM같은 집계 쿼리 사용 불가,의 개수를 세는 등 특별한 방법 필요
- 제품에 대한 계정 변경이 어려움
concat,replace등의 함수를 사용해야 함 (정렬은 불가능)- 특정 처리를 위해 많은 코드 필요
- 유효하지 않은 계정에 대한 검증이 어려움
- 문자열인 경우 구분자 문자를 포함하는 경우 처리가 모호함
- 목록 길이 제한을 정하는 것이 모호함 (각 항목의 길이가 다르면 들어갈 수 있는 항목의 개수가 달라짐)
사용이 합당한 경우
- 반정규화를 적용하여 성능을 향상하기 위함
- 정규화가 우선되어야 하므로 보수적으로 결정 필요
- 목록 안의 개별 값을 분리할 필요가 없는 경우
해법: 교차 테이블 생성
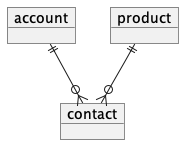
account_id 를 product 테이블이 아닌 별도의 테이블에 저장
이렇듯 어떤 테이블이 FK 로 두 테이블을 참조할 때 교차 테이블(조인 테이블, 다대다 테이블, 매핑 테이블) 이라고 함
product와contact테이블을 통해account쉽게 조회 가능- 제품과 계정에 대한 복잡한 집계 쿼리 가능
- 특정 제품에 대한 계정 변경 쉬움
- FK 를 사용하여 유효한 계정 검증 가능, 참조 정합성 유지
- 구분자 필요하지 않음, 항목 수 제한 없음
- 인덱스를 활용하여 성능 향상
- 각 항목에 속성 추가 가능
3장 순진한 트리: 계층구조 저장 및 조회
답글을 달 수 있고 답글에 대한 답글을 달 수 있다고 가정
데이터가 재귀적 관계를 가지고 트리나 계층 구조를 가질 수 있음
각 항목은 노드라고 부르고 최상위 노드는 뿌리(root) 가장 아래 노드는(leaf)라고 부름
안티패턴: 항상 부모에 의존


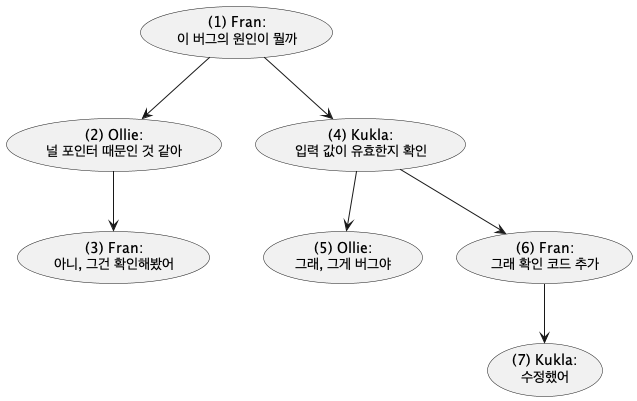
이처럼 같은 테이블 안의 다른 글을 참조하는 설계를 인접 목록(adjacency list) 라고 한다.
- 단계가 깊어질 수록 컬럼을 추가하는 방식으로 후손을 포함하게 됨
- 계속 본인 테이블의 JOIN 문을 추가해야 함
COUNT같은 집계 수치를 계산하기 어려워짐- 다른 방법으로 관련 데이터를 모두 조회하여 애플리케이션에서 트리구조를 만들어줄 수 있음
- 노드를 삭제하기 위해서는 자손을 찾아 가장 아래 단계부터 차례로 삭제 필요
ON DELETE CASCADE로 자동화 가능함- 트리에서 고아 노드 관리가 필요함
사용이 합당한 경우
- 계층적 데이터 작업이 많지 않은 경우
- 주어진 노드의 부모나 자식을 바로 얻을 수 있음
- 새로운 노드 추가가 쉬움
해결책: 대안 트리 모델 사용
- 인적 목록 모델 이외에 다른 모델 사용 (처음에는 복잡해보일 수 있음)
- 경로 열거(Path Enumeration)
- 중첩 집합(Nested Sets)
- 클로저 테이블(Closure Table)
경로 열거(Path Enumeration)
- 일련의 조상을 각 노드의 속성으로 저장
- ex) 디렉터리 구조.
/usr/local/lib에서usr는local의 부모
- ex) 디렉터리 구조.
comment테이블에서parent_id컬럼 대신, 긴VARCHAR타입의path컬럼 정의LIKE구문을 통해 자손과 후손에 대해 조회 가능- 다른 노드를 수정하지 않아도 종단이 아닌 중간 노드 삽입 가능
- 부모 경로를 복사하고 새 노드의 아이디를 조회하여
path변경
- 부모 경로를 복사하고 새 노드의 아이디를 조회하여
breadcrumb을 사용자 인터페이스에 보여줄 때 좋음breadcrumb: 위치를 쉽게 추적, 헨젤과 그레텔의 빵 부스러기에서 유래
- 무단횡단과 비슷한 단점 존재
- 데이터 검증 불가
- 문자열 컬럼의 제한으로 트리의 깊이 제한이 존재
중첩 집합(Nested Sets)
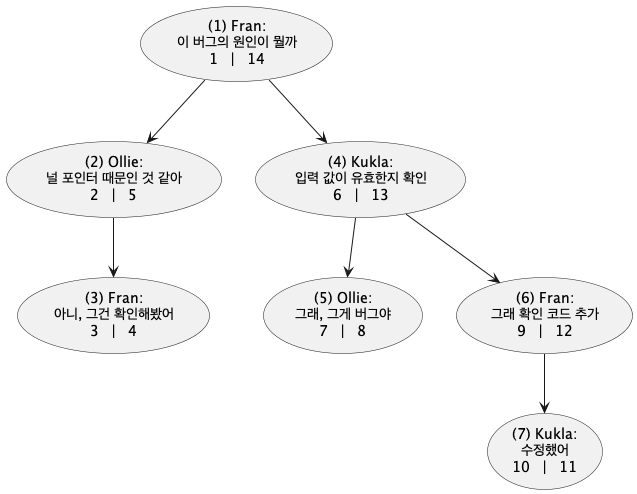
- 부모 대신 자손의 집합에 대한 정보 저장
- 트리의 각 노드를 두 개의 수로 부호화 가능
comment_id와 상관 없음- ex) nsleft 수는 자식 노드의 nsleft 보다 작고, nsright 는 자식의 nsright 보다 큼
- 노드 숫자 사이로 조상 및 자손 조회 가능
- 자식을 가진 노드를 삭제해도 그 자손이 자동으로 삭제된 노드 부모의 자손이 됨
- 노드를 삭제하여 숫자 간격이 생겨도 트리구조에 문제가 되지 않음
- 트리 수정없이 조회를 많이 하는 경우 적합
- 단점
- 새로운 노드를 추가하는 경우 모든 노드의 값을 다시 계산해야 함
- 트리에 노드를 삽입하는 경우가 많다면 중첩 집합은 적합하지 않음
- 직접 적인 부모 찾는 쿼리처럼 일부 쿼리가 복잡해질 수 있음
- 대상의 조상 중 부모와 자식 노드 사이에 노드가 없는 경우를 찾아야 함
- 새로운 노드를 추가하는 경우 모든 노드의 값을 다시 계산해야 함
클로저 테이블(Closure Table)
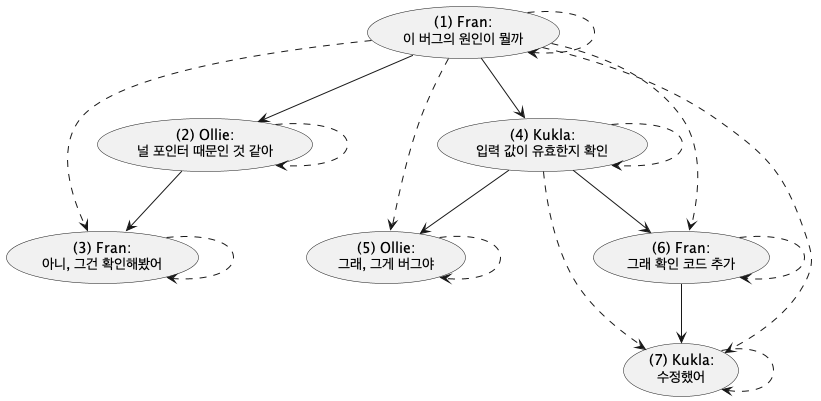
- 계층구조를 저장하는 단순한 방법
- 부모-자식 관계 뿐만 아니라 트리의 모든 경로 저장
- 트리의 정보를
comment테이블이 아닌 트리 구조를 저장하는 새로운 테이블 생성- ex)
tree_path라는 테이블 생성
- ex)
- 조상이나 자손을 조회하는 쿼리가 직관적임
- 새로운 종말 노드를 추가하려면 자기 자신을 참조하는 행 추가
- 융통성있는 모델이지만 많은 저장 공간을 필요로 함
- 다양한 속성을 추가해 테이블 개선 가능
- ex)
path_length를 추가하여 트리의 깊이 조회 가능
- ex)
| 모델 | 테이블 | 자식 조회 | 트리 조회 | 삽입 | 삭제 | 참조 정합성 |
|---|---|---|---|---|---|---|
| 인접 목록 | 1 | 쉽다 | 어렵다 | 쉽다 | 쉽다 | 가능 |
| 재귀적 쿼리 | 1 | 쉽다 | 쉽다 | 쉽다 | 쉽다 | 가능 |
| 경로 열거 | 1 | 쉽다 | 쉽다 | 쉽다 | 쉽다 | 불가능 |
| 중첩 집합 | 1 | 어렵다 | 쉽다 | 어렵다 | 어렵다 | 불가능 |
| 클로저 테이블 | 2 | 쉽다 | 쉽다 | 쉽다 | 쉽다 | 가능 |
4장 아이디가 필요해: 중복행 방지
- 아무런 의미도 가지지 않는 인위적인 값을 PK 로 사용하는 형태를 가상키(pseudokey) 또는 대체키(surrogate key) 라 함
- 대부분의 DBMS 에서는 가상키 값이 유일하게 할당되는 것을 보장하기 위한 메커니즘 제공
- ex)
AUTO_INCREMENT,GENERATOR,IDENTITY,ROWID,SEQUENCE,SERIAL
- ex)
- 대부분의 DBMS 에서는 가상키 값이 유일하게 할당되는 것을 보장하기 위한 메커니즘 제공
- PK 는 테이블 내의 유일함을 보장
- 각 행에 접근하는 논리적 메커니즘
- 중복 행이 저장되는 것을 방지
- PK 관계를 생성할 때 FK 로부터 참조
안티패턴: 만능키
모든 테이블에 다음과 같은 특성의 PK 칼럼 추가
- 칼럼 이름은
id - 데이터 타입은 32 비트 또는 64비트 정수
- 유일한 값은 자동 생성
특징
- 중복 키 생성
id컬럼을 정의하고 테이블에 UNIQUE 제약조건이 설정된 컬럼을 추가- ex)
id가 있지만bug_id키 추가
- 중복 행 허용
- 교차 테이블에서는 복합키를 통해 유일한 값을 보장해야 함
id칼럼을 사용하는 경우 두 칼럼에 제약조건이 적용되지 않음UNIQUE제약조건을 걸어야 한다면id칼럼은 불필요
- 모호한 키의 의미
id라는 의미는 일반적이기 때문에 아무런 의미를 가지지 못함- 어떤 테이블의
id인지 구분이 어려움
- 어떤 테이블의
bug_id,account_id같은 이름이 가독성이 좋음
- USING 사용 불가능
id를 사용하면 이름이 다르기 때문에 불가능- 두 테이블에서 컬럼 이름이 같다면 간략한 문법 사용 가능
- ex)
SELECT * FROM bug JOIN bug_product USING (bug_id);
- ex)
- 어려운 복합키
id를 사용하지 않으면 복합키 필요- 복합 PK 를 참조하려면 복합 FK 가 되어야 함
- 쿼리가 복잡해짐
사용이 합당한 경우
id가상키 관례를 따르는 객체-관계 프레임워크를 사용하는 경우- ex) CoC (Convention over Configuration)
- 지나치게 긴 자연키를 대체하기 위함
- ex) 파일 경로 - 긴 문자열을 키로 한다면 많은 인덱스 유지 비용 발생
해법: 상황에 맞추기
정해진 관례를 무조건 따르지 않고 상황에 맞게 선택
- 있는 그대로 말하기
- 의미있는 PK 이름 사용 (ex.
bug테이블의 PK 는bug_id) - 본질을 더 잘 표현 하는 경우, FK 를 PK 이름과 다르게 설정 (ex.
bug의reported_by)
- 의미있는 PK 이름 사용 (ex.
- 관례에서 벗어나기
- 사용하는 프레임워크의 설정을 변경
- 의미 있는 컬럼 이름 사용하는 것이 중요
- 자연키와 복합키 포용
- 자연키로 적당했던 컬럼이 중복이 허용되도록 변경될 수도 있음
- 복합키가 적절한 경우에 복합키 사용
- 참조하는 FK 도 복합키가 되어야 하므로 주의
- 중복된 칼럼 값을 얻을 때 조인을 안해도 되는 장점이 생김
5장 키가 없는 엔트리: 데이터베이스 아키텍처 단순화
다음과 같은 상황으로 인해 참조 정합성 제약조건(또는 FK)을 사용하지 말라는 경우가 있음
- 데이터 업데이트 시 제약조건과 충돌
- 참조 정합성 제약조건 또는 FK 를 지원하지 않는 데이터베이스 설계
- FK 에 자동 생성되는 인덱스로 인해 성능에 영향을 받음
- FK 선언을 위해 문법을 찾아봐야 함
안티패턴: 제약조건 무시
외래 키 제약조건을 생략하면 다른 방식으로 정합성 유지가 필요해짐
- 무결점 코드
- 행을 추가, 삭제할 때마다 값이 존재여부 확인 필요
- 높은 동시성(concurrency)과 확장적응성(scalability)이 필요한 환경에서 제대로 동작하지 않음
- 오류 확인
- 손상된 데이터를 찾기위해 자주 확인 필요
- 오류를 발견해도 어떤 값으로 맞춰야 할 지 바로잡기 어려움
- “내 잘못이 아냐”
- 데이터베이스를 건드리는 모든 코드가 완벽하지 않음
- 코드를 수정해도 모든 경우에 대해 문제가 없는지 확신이 어려움
- 진퇴양난 업데이트
- FK 제약조건을 위반하지 않기 위해 여러 컬럼 실행 필요
- 자식 행이 참조하는 컬럼을
UPDATE하는 경우 처리가 어려워짐- 자식 행 업데이트 전 부모 행 업데이트 불가, 부모 행 업데이트 전 자식행 업데이트 불가
사용이 합당한 경우
- FK 제약조건을 지원하지 않는 데이터베이스
- 품질 제어 스크립트 같은 것으로 보완 필요
해법: 제약조건 선언하기
- FK 사용하여 처음부터 잘못된 데이터가 입력되지 않도록 설정
- 불필요한 코드 작성할 필요 없음
- 모든 코드가 동일한 제약조건을 따르는 것을 확신 가능
여러 테이블 변경 지원
단계적 업데이트(cascading update) 기능 지원
- 부모 행을 업데이트 또는 삭제하는 경우 자식 행을 알아서 처리 (진퇴양난 문제 해결)
ON UPDATE,ON DELETE선언 방식에 따라 결과 제어 가능CASCADE: 다른 행에서 대상 행을 참조하고 있으면 함께 변경/삭제 됨RESTRICT: 다른 행에서 대상 행을 참조하고 있으면 변경/삭제되지 않고 오류 발생NO ACTION: MYSQL 에서는RESTRICT와 동일SET NULL: 대상 행에서 대상 행을 참조하고 있으면 값을NULL로 변경
오버헤드
약간의 오버헤드가 있을 수 있지만, FK 가 더 효율적
- 데이터 확인을 위한
SELECT쿼리 불필요 - 여러 테이블 변경을 위해 테이블 잠금 불필요
- 고아 데이터를 정정하기 위한 품질 제어 스크립트 불필요
6장 엔티티-속성-값: 가변 속성 지원
객체지향 프로그래밍 모델에서 데이터 타입을 상속하는 것과 같은 방법으로 관계를 가질 수 있다.
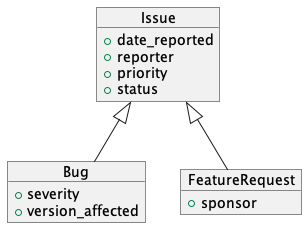
버그 데이터베이스로 예를 들어,
Bug 와 FeatureRequest 는 베이스 타입인 Issue 속성을 공통으로 가지고 각자 다음 속성들을 갖는다.
Bug: 제품의 버전, 중요도, 영향도
FeatureRequest: 예산을 지원하는 스폰서
안티패턴: 범용 속성 테이블 사용
별도 테이블을 생성해 속성을 행으로 저장하는 방식
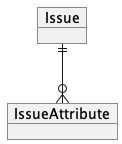
- 엔티티 (Entity)
- 속성하나의 엔티티에 대해 하나의 행을 가지는 부모 테이블에 대한 FK
- 속성 (Attribute)
- 일반 테이블에서의 컬럼 역할
- 속성이 하나씩 들어감
- 값 (Value)
- 속성에 대한 값을 가짐
이 설계는 엔티티-속성-값(Entity-Attribute-Value) 또는 EAV, 오픈 스키마(open schema), 스키마리스(schemaless), 이름-값(name-value pairs) 으로 불리기도 함
- 장점
- 두 테이블 모두 적은 컬럼을 가짐
- 새로운 속성을 지원하기 위해 컬럼을 추가할 필요가 없음
- 특정 속성이 필요 없는 경우
NULL을 채워도 되지 않음
- 속성 조회
- 문자열로 속성 이름을 지정하여 정보를 조회해야 함
- 일반 조회 쿼리보다 더 복잡하고 명확하지 않음
- 데이터 정합성
- 필수 속성(
NOT NULL) 사용 불가 - 데이터 타입 사용 불가
- 타입마다 컬럼을 선언하여 사용할 수도 있지만 쿼리가 더 복잡해짐
- 참조 정합성 강제 불가
- 속성 이름 강제 불가
- 필수 속성(
- 행을 재구성하기
- 일반적인 테이블에 저장된 것처럼 하나의 이슈를 조회하려면 각 속성에 대해 조인필요
- 속성 개수가 늘어나면 조인 회수도 늘어나고 쿼리 비용도 지수적으로 증가
사용이 합당한 경우
- 다루기 어려워지므로 명심해서 사용해야 함
- 비관계형 기술을 사용하는 경우
- Berkeley DB, Cassandra, CouchDB, Hadoop, MongoDB, Redis…
해법: 서브타입 모델링
단일 테이블 상속 (Single Table Inheritance)
- 모든 타입을 하나의 테이블에 저장하고, 각 타입에 있는 모든 속성을 별도의 칼럼으로 저장
- 서브타입을 나타내기 위한 속성 필요 (ex.
issue_type) - 해당 속성이 적용되지 않는 객체의 경우
NULL로 채움 - 새로운 객체 타입이 생기면 해당 타입의 속성도 수용하기 위해 컬럼 추가 필요
- 적용하기 좋은 경우
- 서브타입 개수가 적은 경우
- 특정 타입에만 속하는 속성의 개수 적은 경우
- 단일 테이블 데이터베이스 접근 패턴을 사용하는 경우
구체 테이블 상속 (Concrete Table Inheritance)
- 적용되지 않는 속성이 없도록 강제 가능
- 단일 테이블 상속처럼 부가적인 서브타입을 나타내는 속성이 필요 없음
- 공통 속성을 인지하기 어렵고, 공통 속성이 추가되면 모든 서브타입 테이블 변경이 필요
- 모든 서브타입을 조회할 필요가 없는 경우에 적합
- 서브타입이 별도 테이블에 저장된 경우, 모든 객체를 보기가 복잡
클래스 테이블 상속 (Class Table Inheritance)
- 객체지향 클래스인 것처럼 생각하여 상속을 흉내
- 공통인 속성을 포함하는 베이스 타입을 위한 테이블 생성
- 서브타입을 나타내기 위한 속성이 필요 없음
- 모든 서브타입에 대한 조회가 많고 공통 컬럼을 자주 참조하는 경우에 적합
반구조적 데이터 (Semistructured Data)
- 데이터의 속성 이름과 값을 XML 또는 JSON 형태로 저장
- 새로운 속성을 언제든 저장할 수 있기 때문에 확장이 쉬움
- 다른 속성 집합을 가질 수 있어서 각 행마다 서브 타입을 가질 수 있음
- 데이터베이스에서 특정 속성에 대해 지원하지 않는다면 조회가 어렵고, 복호화 코드 필요
- 완전한 유연성이 필요한 경우 적합
사후 처리
SELECT issue_id, attribute_name, attribute_value
FROM issue_attribute
WHERE issue_id = 1234;
- EAV 설계를 사용할 수 밖에 없는 경우
- 단일 행으로 조회하는 것이 아닌, 관련된 속성을 모두 조회하여 애플리케이션 코드에서 처리
7장 다형성 연관: 여러 부모 참조
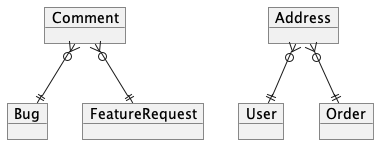
하나의 댓글(comment) 테이블에 대해 버그(bug) 와 기능요청(feature_request) 에 대한 댓글을 저장하고 싶다.
하지만 여러 개의 부모 테이블을 참조하는 FK 를 생성은 불가능하다.
서브 타입이 아닌 관련 되지 않은 경우에도 이러한 문제는 동일하다.
안티패턴: 이중 목적의 FK 사용
이와 같은 경우, 다형성 연관(polymorphic Associations) 또는 난잡한 연관 (promiscuous associations) 이라고도 불리는 해법을 활용한다.
다형성 연관 정의
- 현재 행이 참조하는 부모 테이블 이름을 저장하는 컬럼 추가 (ex.
issue_type,parent_table) - 여러 부모 테이블들의 PK 값을 저장할 수 있는 컬럼 필요 (ex.
issue_id,parent_id) - 여러 테이블에 대해 참조하기 때문에 FK 선언 불가
- 조인할 때, 부모 테이블 이름을 정확하게 명시해야 함
- 모두 다른 테이블과 연관되어 있는 경우, 테이블 조인이 불가능
- 외부 조인을 하는 쿼리를 활용하면 매칭되지 않는 필드는
NULL로 됨
사용이 합당한 경우
- 객체-관계 프로그래밍 프레임워크를 사용하는 경우 (ex. Hibernate)
해법: 관계 단순화
관계의 방향성을 거꾸로 하는 역 참조 방법으로 해결
- 교차 테이블 생성
- 각 부모에 대해 교차 테이블을 생성하여 여러 개의 FK 사용
- ex)
bug_comment,feature_request_comment - 자식 테이블에서 부모 테이블의 타입을 저장하는 컬럼이 필요하지 않음
- ex)
- 데이터 정합성 강제 가능
- 신호등 설치 - 허용하고 싶지 않은 연관이 생길 수 있는 문제 발생
- 자식 테이블의 특정 행이 같은 부모 테이블의 여러 행과 연관되지 않도록
UNIQUE제약조건 추가 - 특정 행이 여러 부모 테이블에 대해 참조되는 것은 방지 불가 (어플리케이션 코드의 책임)
- 자식 테이블의 특정 행이 같은 부모 테이블의 여러 행과 연관되지 않도록
- 양쪽 다 보기
- 특정 부모 테이블에 대한 데이터는 교차 테이블을 이용해 간단하게 조회 가능
- 참조 정합성에 의존하여 조회 가능
- 차선 통합 - 여러 부모 테이블의 결과를 하나의 테이블처럼 보여줘야 하는 경우
UNION을 통해 결과를 묶을 수 있음COALESCE0()함수를 사용하여 존재하는 한쪽 부모 테이블의 필드만 나열하여 묶을 수 있음
- 각 부모에 대해 교차 테이블을 생성하여 여러 개의 FK 사용
- 공통 수퍼테이블 생성
- 부모 테이블이 상속할 베이스 테이블 생성하여 문제 해결
- ex)
issue공통 테이블 생성,comment는issue을 참조
- ex)
- 부모 테이블 이름을 저장하는 컬럼이 필요하지 않음
- FK 제약조건이 직접 연결되어 있지 않아도 정합성을 강제하면서 조인도 가능
- 부모 테이블이 상속할 베이스 테이블 생성하여 문제 해결
8장 다중 컬럼 속성: 다중 값 속성 저장
2장 무단횡단 안티패턴과 동일한 목표
여러 개의 값을 저장하고 싶은 경우
ex) 전화번호 - 보조 휴대폰, 사무실, 팩스 번호 등
안티패턴 : 여러 개의 칼럼 생성
- 각 컬럼에 하나의 값만 저장하기 위해 여러 개의 칼럼을 생성
- ex)
tag1,tag2,tag3…
- ex)
- 값 검색
- 관련된 컬럼들에 대해 조회가 필요하다면
OR또는IN조건을 사용해야 함 - 여러 값에 대해서도 조회가 필요하다면
WHERE절이 길어짐
- 관련된 컬럼들에 대해 조회가 필요하다면
- 값 추가와 삭제 - 어느 컬럼이 비어있는지 확인하기 위한 조회 필요
- 동시성 문제가 발생될 수 있음 (충돌 또는 덮어쓰기)
- 복잡한 SQL 을 이용하면 한번에 해결도 가능
NULLIF함수를 이용하여 동일한 대상 값 삭제 가능COALESCE함수를 이용하여 빈 칼럼에 값 추가 가능
- 유일성 보장 불가
- 값의 수 증가 처리 - 테이블 변경 필요
- 테이블 구조를 변경하려면 잠금 설정하고, 클라이언트 접근 차단 과정 필요
- 예전 테이블에서 모든 데이터를 새로운 테이블로 복사하고, 예전 테이블 삭제하는 과정은 많은 시간 소요
- 컬럼을 추가하면 관련된 모든 SQL 문을 확인해 지원되도록 수정 필요
사용이 합당한 경우
- 속성의 개수가 고정되고 선택의 위치나 순서가 중요한 경우
- 각 속성의 사용처가 다른 경우 (논리적으로 다른 속성)
해법: 종속 테이블 생성
- 종속 테이블 생성하고 FK 정의
- 주어진 태그에 대한 검색이 직관적
- 행 추가 삭제도 단순해짐
- 중복이 허용되지 않도록 제약조건을 추가하여 유일성 보장
- 제한되지 않은 컬럼 개수
9장 메타데이터 트리블: 확장 적응성 지원
데이터 양이 늘어나면 쿼리 성능 저하됨
크기가 늘어나도 쿼리 성능을 향상 시킬 수 있도록 데이터베이스 구성
안티패턴 : 테이블 또는 칼럼 복제
- 많은 행을 가진 큰 테이블을 작은 테이블로 분리
- 작은 테이블의 이름을 테이블의 속성 중 하나의 값을 기준으로 지정
- 하나의 칼럼을 여러 개의 칼럼으로 분리
- 칼럼 이름은 다른 속성의 값을 기준으로 지정
위와 같이 두 가지의 형태의 안티패턴이 존재
이렇게 구성하게 되면 테이블 수나 칼럼 수가 계속 증가하게 됨
- 테이블이 우글우글
- 데이터를 분리해 별도의 테이블에 넣으려면 어떤 테이블로 보낼지 정책 필요
- 나눠지는 정책이나 값이 변경되면 애플리케이션 에러 발생
- 새로운 데이터 값이 들어오면 새로운 메타데이터 객체가 필요
- 데이터 정합성 관리
- 조건이 올바르지 않는 데이터가 존재하지 않아야 함
- 테이블 생성 시,
CHECK제약 조건을 통해 제한 가능
- 데이터 동기화
- 데이터를 변경하는 경우, 한 테이블에서 삭제하고 다른 테이블에 삽입해야할 수 있음
- 유일성 보장
- 유일성을 보장하기 위해서는 PK 값 생성만을 위한 새로운 테이블 정의 필요
- 여러 테이블에 걸쳐 조회
- 여러 테이블에 걸쳐 조회해야 하는 경우,
UNION으로 묶어야 함
- 여러 테이블에 걸쳐 조회해야 하는 경우,
- 메타데이터 동기화
- 테이블 컬럼을 추가하기 위해서는 모든 테이블에 컬럼 추가 필요
- 와일드카드(
*) 사용이 어렵고 이름 지정 필요
- 참조 정합성 관리
- 다른 테이블에서 해당 테이블에 대해 FK 선언 불가
JOIN되는 경우,UNION으로 묶어서 조회 필요
- 메타데이터 트리블 칼럼 식별하기
- 컬럼도 동일하게 메타데이터 트리블이 발생
사용이 합당한 경우
- 현재 데이터와 오래된 데이터를 함께 조회할 필요가 없는 경우
- 오래된 데이터를 다른 위치로 옮기고 해당 테이블에서 삭제
해법: 파티션과 정규화
- 수평 분할(horizontal partitioning) 사용
- 규칙을 정해 행을 여러 파티션으로 분리
- 물리적으로 분리되어 있지만, 하나의 테이블처럼 사용 가능
- 별도 스토리지로 분리 가능
- 행이 잘못된 테이블로 들어갈 문제가 없음
- 물리적인 테이블 개수를 직접 지정할 수 있음
- 규칙을 정해 행을 여러 파티션으로 분리
- 수직 분할(vertical partitioning) 사용
- 크기가 큰 컬럼이나 거의 사용되지 않은 컬럼이 있는 경우 유리
- 와일드카드(
*)를 사용하면 해당 컬럼도 모두 조회하게 되므로 성능 저하 발생될 수 있음 - ex)
BLOB,TEXT
- 와일드카드(
- 행이 고정 크기인 경우 조회 성능이 좋으므로 가변 길이 컬럼을 별도 테이블로 저장하면 성능 향상
- ex)
VARCHAR
- ex)
- 크기가 큰 컬럼이나 거의 사용되지 않은 컬럼이 있는 경우 유리
- 메타데이터 트리블 컬럼 고치기
- 메타데이터 트리블 컬럼에 대해 종속 테이블 생성
- 함께 조회하는 경우가 드문 경우 사용
- 함께 조회하는 경우가 많다면 오히려 성능 저하 발생
관련 코드는 깃허브 참고
출처
- SQL AntiPatterns