운영체제 아주 쉬운 세가지 이야기 책에 대한 스터디를 진행한다.
이 글에서는 가상화에 대해 다룬 7장부터 11장까지의 내용으로 CPU 가상화를 마무리한다.
7장. 스케줄링: 개요
이 장에서는 다양한 스케줄링 정책(scheduling policy) 에 대해 소개한다.
7.1 워크로드에 대한 가정
워크로드(workload) 는 프로세스가 동작하는 일련의 행위를 의미한다.
스케줄링 정책 개발을 위해서는 적절한 워크로드 선정이 중요하다.
시스템에서 실행 중인 프로세스 또는 작업(job) 에 대해 다음과 같은 가정을 한다.
- 모든 작업은 같은 시간 동안 실행
- 모든 작업은 동시에 도착
- 작업은 일단 시작하면 최종적으로 종료될 때까지 실행
- 모든 작업은 CPU만 사용
- 작업의 실행 시간은 사전에 알려져 있음 (매우 비현실적)
7.2 스케줄링 평가 항목
스케줄링 정책 평가를 위해 스케줄링 평가 항목(scheduling metric) 결정 필요
반환 시간(turnaround time)
작업이 완료된 시각에서 작업이 도착한 시각을 뺀 시간 (성능 측면 평가)
모든 작업은 동시에 도착한다고 가정했으므로 T(arrival) = 0
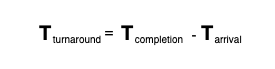
공정성(fairness)
Jain`s Fairness Index 라는 지표가 공정성 지표의 한 예
성능과 공정성은 스케줄링에서 서로 상충 (ex. 성능을 극대화하기 위해 다른 작업에게 실행 기회를 안줄 수 있음)
7.3 선입선출
선입선출(First In First Out, FIFO) 또는 선도착선처리(First Come First Served, FCFS) 은 가장 기본적인 알고리즘
단순하고 구현하기 쉽고 세워놓은 가정 하에서는 잘 동작한다.
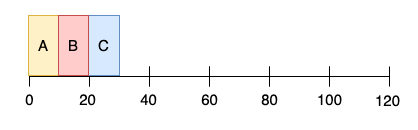
작업 3개가 거의 동시에 들어왔다고 가정하면 위 작업의 평균 반환 시간은 (10+20+30) / 3 = 20
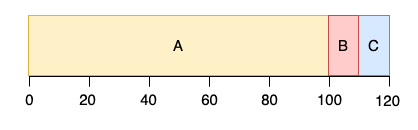
하지만 가정 1(모든 작업은 같은 시간 동안 실행)이 없어져서 작업 A 가 100초 동안 실행된다면 평균 반환시간은 (100+110+120) / 3 = 110 으로 된다.
이 현상을 convoy effect 라고 한다.
CPU 가 많이 필요하지 않은 프로세스들이 오랫동안 CPU 를 사용하는 프로세스를 기다리는 현상을 의미
7.4 최단 작업 우선
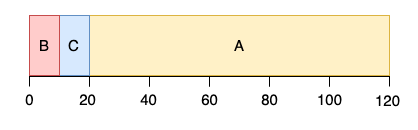
convoy effect 문제는 최단 작업 우선(Short Job First, SJF) 으로 해결한다.
이 기법은 짧은 시간을 가진 작업을 먼저 실행한다.
평균 반환시간은 (10+20+120) / 3 = 50 으로 2배 이상 향상됐다.
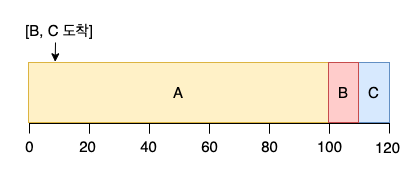
하지만 가정 2(모든 작업은 동시에 도착)가 없어져서 작업이 임의의 시간에 도착한다면 또 다른 문제가 발생된다.
B 와 C 가 늦게 도착한다면 A 를 기다릴 수 밖에 없어서 convoy effect 문제가 다시 발생된다.
7.5 최소 잔여시간 우선
이 문제를 해결하기 위해서는 가정 3(작업은 일단 시작하면 최종적으로 종료될 때까지 실행)을 제거하여 작업을 실행 도중에 중단해야 한다.
위에서 다룬 SJF 는 비선점형 스케줄러이기 때문에 실행중인 작업을 중단하지 못한다.
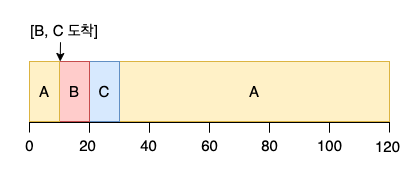
최단 잔여시간 우선(Shortest Time-to-Completion First, STCF) 또는 선점형 최단 작업 우선(PSJF) 는 SJF 에 선점 기능을 추가했다.
새로운 작업이 도착하면 실행중인 작업의 잔여 시간과 비교하여 가장 작은 작업을 스케줄 한다.
7.6 새로운 평가 기준: 응답 시간
시분할 컴퓨터가 등장하면서 사용자는 상호작용을 원활히 하기 위해 성능을 요구하게되었다.
응답 시간(response time) 이라는 평가 기준이 추가되었다.
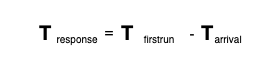
응답 시간은 작업이 도착하는 시점부터 처음으로 스케줄 될 때까지의 시간이다.
반환 시간이 좋아도 다른 작업이 먼저 스케줄되어 응답이 계속 늦어진다면 상호작용 측면에서 매우 불편할 것이다.
7.7 라운드 로빈
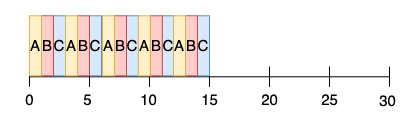
응답 시간 문제를 해결하기 위해 라운드 로빈(Round-Robin, RR 또는 타임 슬라이싱) 스케줄링이 도입된다.
RR 은 작업이 끝날 때까지 기다리지 않고 일정 시간동안 실행하고 실행 큐의 다음 작업으로 전환한다.
작업이 실행되는 일정 시간을 타임 슬라이스(time slice) 또는 스케줄링 퀀텀(scheduling quantum) 이라 하고
이 시간은 타임 인터럽트 주기의 배수여야 한다.
RR 은 공정한 정책으로 응답 시간에 대한 성능은 좋지만 반환 시간 측정 기준으로는 최악이다.
타임 슬라이스가 너무 짧으면 문맥 교환(context switch) 이 자주 발생되어 성능에 큰 영향을 미친다.
문맥 교환 비용을 상쇄할 수 있을 만큼길고 응답 시간이 길지 않은 적절한 타입슬라이스의 길이를 결정해야 한다.
7.8 입출력 연산의 고려
모든 프로그램은 입출력 작업을 수행하도록 가정 4(모든 작업은 CPU만 사용) 를 제거한다.
실행중인 프로세스가 입출력 작업을 요청하면 스케줄러는 어떤 작업을 실행할지 결정해야 한다.
반대로 입출력 완료되어 인터럽트가 발생하고 프로세스가 대기에서 준비 상태로 변경되면 어떤 프로세스를 실행할지 결정해야 한다.
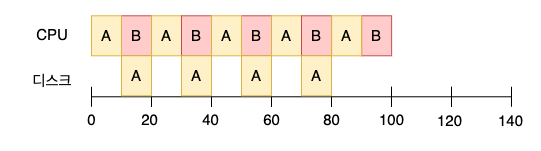
STCF 스케줄러를 이용하여 두 작업 A, B 를 처리한다.
A 는 입출력 작업 요청으로 5개의 10 msec 작업, B는 한번에 50 mesc 사용한다.
STCF 은 우선 가장 짤은 작업인 A를 선택한다.
A 첫 번째 소 작업이 완료되면 B 를 실행하고 다음 A 가 도착하면 다시 A 를 실행한다.
하나의 프로세스가 입출력 완료를 대기하는 동안 다른 프로세스가 CPU 를 사용하여 연산의 중첩이 가능해져 시스템 사용률을 향상시킬 수 있다.
7.9 만병통치약은 없다(No More Oracle)
일반적인 운영체제에서 작업의 길이를 미리 알 수 없다. (가정 5)
사전 지식 없이 SJF/STCF 알고리즘 구축과 RR 스케줄러의 아이디어를 도입하는 것은 쉽지 않다.
8장 스케줄링: 멀티 레벨 피드백 큐
이 장에서 가장 유명한 스케줄링 기법인 멀티 레벨 피드백 큐(Multi-level Feedback Queue, MLFQ) 에 대해 알아본다.
MLFQ 는 다음 두 가지 문제를 해결하고자 한다.
- 짧은 작업을 먼저 실행하여 반환 시간 최적화
- 운영체제는 실행 시간을 미리 알 수 없음
- 응답 시간 최적화
- RR 은 응답 시간이 단축되지만 반환 시간이 최악
8.1 MLFQ: 기본 규칙
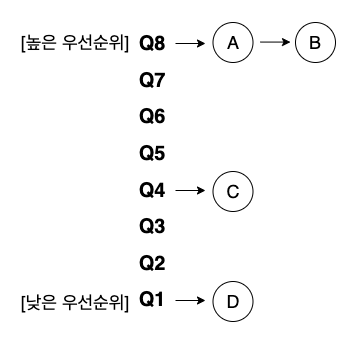
- MLFQ 은 여러 개의 큐로 구성
- 큐는 우선 순위(priority level) 가 각각 다르게 배정
- 높은 우선순위 큐에 존재하는 작업이 우선 선택
- 우선 순위는 작업의 특성에 따라 동적으로 부여
- ex) 반복적으로 CPU 를 양보하면 우선순위가 높고, CPU 를 집중적으로 사용하면 우선순위를 낮춤
- 작업이 진행되는 동안 정보를 얻어 미래 행동을 예측
- 큐에는 둘 이상의 작업이 존재할 수 있고, 모두 같은 우선순위
- 우선순위가 동일하면 라운드 로빈 스케줄링 알고리즘 사용
MLFQ 은 다음 두 가지 규칙이 존재한다.
- 규칙 1
- Priority(A) > Priority(B) 라면, A가 실행 (B는 실행되지 않음)
- 규칙 2
- Priority(A) = Priority(B) 라면, A와 B는 RR 방식으로 실행
시도 1: 우선순위 변경
MLFQ 가 작업 우선순의를 어떻게 변경하는지 결정이 필요 우선순위 조정 알고리즘을 위해 첫번째 시도는 다음과 같다.
- 규칙 3: 작업이 시스템에 진입하면, 가장 높은 우선순위 큐에 추가
- 규칙 4a: 주어진 타임 슬라이스를 모두 사용하면 우선순위가 한 단계 아래 큐로 낮아짐
- 규칙 4b: 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위 유지
예 1: 한 개의 긴 실행 시간을 가진 작업
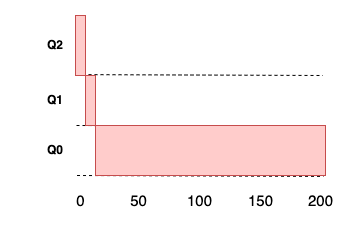
- 작업은 최고 우선 순위로 진입
- 10 msec 타임 슬라이스가 지나면 우선 순위를 한 단계 낮춰 Q1 로 이동
- 다시 타임 슬라이스가 지나면 Q0으로 이동 후 계속 머무르게 됨
예 2: 짧은 작업과 함께
MLFQ 는 짧은 작업이면 빨리 실행되고 종료하기 때문에 SJF 에 근사할 수 있음
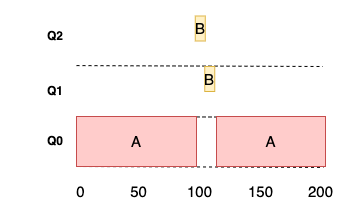
A 는 오래 실행되는 CPU 위주 작업 B 는 짧은 대화형 작업
- A 는 가장 낮은 우선순위 큐에서 실행 중
- B 는 T = 100 에 가장 높은 우선순위 큐로 진입
- B 는 두번의 타임 슬라이스를 소모하며 종료
- A 낮은 우선순위에서 실행 재개
예 3: 입출력 작업에 대해서는 어떻게?
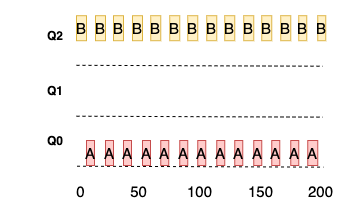
프로세스가 타임 슬라이스 소진 전에 프로세서를 양도하면 같은 우선 순위 유지 (규칙 4b)
즉, 대화형 작업이 자주 입출력을 수행하면 타임 슬라이스가 종료되기 전에 CPU를 양도하여 우선 순위 유지
B 는 대화형 작업으로 짧게 실행하고 CPU 를 계속 양도하며 높은 우선 순위 유지 A 는 긴 배치형 작업으로 CPU 를 사용하기 위해 경쟁
현재 MLFQ 의 문제점
- 문제점 1. 기아 상태(starvation) 발생 가능
- 너무 많은 대화형 작업들이 존재하면 그 작업들이 CPU 시간을 소모하고 긴 실행 시간 작업은 CPU 할당받지 못하고 죽을 수 있음
- 문제점 2. 스케줄러를 자신에게 유리하게 프로그램 작성
- 스케줄러를 속여서 지정된 몫보다 많은 시간을 할당하도록 만들 수 있음 (CPU 독점 가능)
- 문제점 3. 프로그램은 시간 흐름에 따라 특성이 변할 수 있음
- CPU 위주 작업이 대화형 작업으로 바뀔 수 있지만 다른 대화형 작업들과 같은 대우를 받을 수 없음
8.3 시도 2: 우선순위 상향 조정
기아 문제를 방지하기 위한 간단한 방법은 모든 작업의 우선순위를 상향 조정(boost) 하는 것이다.
- 규칙 5: 일정 기간 S 가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
이 규칙으로 다음 두 가지 문제가 해결된다.
- 프로세스가 굶지 않도록 보장 (문제점 1)
- CPU 위주의 작업이 대화형 작업으로 변경되면 적합한 스케줄링 기법 적용 가능(문제점 3)
하지만 S 가 너무 크면 긴 실행 시간을 가진 작업은 기아 상태가 발생될 수 있고
너무 작으면 적절한 양의 CPU 시간 사용 불가능하다. (부두 상수, vod-doo constants)
8.4 시도 3: 더 나은 시간 측정
스케줄러를 자신에게 유리하게 동작시키는 것(문제점 2)을 해결하기 위한 방법은 각 단계에서 CPU 총 사용 시간을 측정하는 것이다.
현재 단계에서 소진한 CPU 사용 시간을 저장하여 타임 슬라이스에 해당하는 시간을 모두 소진하면 우선순위를 낮춤
규칙 4a(주어진 타임 슬라이스를 모두 사용하면 우선순위가 한 단계 아래 큐로 낮아짐) 와 규칙 4b(타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위 유지) 를 하나의 규칙으로 재정의한다.
- 규칙 4: 주어진 단계에서 시간 할당량을 소진하면(CPU 양도 횟수 상관 없이), 우선순위는 낮아진다.
8.5 MLFQ 조정과 다른 쟁점들
- 스케줄러가 필요한 변수들에 대해 설정 방법 파악 필요
- ex) 큐의 갯수, 타임 슬라이스 크기, 우선순위 상향 조정 빈도 …
- 워크로드에 대해 경험하고 조정해나가면서 균형점을 찾아야 함
- 다른 MLFQ 는 위에서 정의한 규칙을 사용하지 않음
- 수학 공식을 사용하여 우선순위 조정
8.6 MLFQ: 요약
- 규칙 1. 우선순위(A) > 우선순위(B) 일 경우, A가 실행, B는 실행되지 않는다.
- 규칙 2. 우선순위(A) = 우선순위(B), A와 B는 RR 방식으로 실행된다.
- 규칙 3. 작업이 시스템에 들어가면 최상위 큐에 배치된다.
- 규칙 4. 작업이 지정된 단계에서 배정받은 시간을 소진하면(CPU 양도 횟수와 관계 없이), 작업의 우선순위는 감소한다.
- 규칙 5. 일정 주기 S가 지난 후, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
9장. 스케줄링: 비례 배분
비례 배분(Proportional Share) 스케줄러, 혹은 공정 배분(fair share) 이라고 불리는 스케줄러에 대해 알아본다.
비례 배분은 반환 시간이나 응답 시간을 최적화하는 대신 CPU 의 일정 비율을 보장하는 것이 목적
더 자주 수행되어야 하는 프로세스는 기회를 더 많이 줌(추첨 스케줄링, lottery scheduling)
9.1 기본 개념: 추첨권이 당신의 지분이다.
추첨권(티켓) 이라는 개념이 추첨 스케줄링의 근간이다.
추첨권은 특정 자원에 대한 지분을 나타내는 것으로 소유한 티켓 개수와 전체 티켓간의 비율이 자신의 몫이다.
추첨 스케줄러는 타임 슬라이스가 끝날 때마다 추첨권의 총 개수를 파악하고 추첨권을 뽑아 다음 실행 프로세스를 결정한다.
9.2 추첨 기법
- 추첨권 화폐(ticket currency)
- 사용자가 추첨권을 자신의 화폐 가치로 추첨권을 할당할 수 있도록 허용
- 시스템은 자동으로 화폐 가치 변환
- 추첨권 양도(ticket transfer)
- 양도를 통해 일시적으로 추첨권을 다른 프로세스에게 넘겨줌
- 클라이언트/서버 환경에서 유용 (클라리언트가 서버에게 전달하여 성능 극대화)
- 추첨권 팽창(ticket inflation)
- 프로세스는 일시적으로 소유한 추첨권의 수를 늘이거나 줄일 수 있음
- 프로세스들이 서로 신뢰할 때 유용
- 더 많은 CPU 을 필요로 한다면 시스템에게 알려 혼자 추첨권의 가치 상향 조정
9.3 구현
추첨 스케줄링의 가장 큰 장점은 구현이 단순하다는 것이다.
- 필요 사항
- 난수 발생기
- 프로세스들의 자료 구조
- 추첨권의 전체 개수
리스트를 내림차순으로 정렬하면 가장 효율적 (검색 횟수가 최소화 보장)
int counter = 0;
int winner = getrandom(0, totaltickets); // 난수 발생기
node_t * current = head; // 작업 목록 탐색
while(current) {
counter = counter + current->tickets; // 추첨권 개수 더하기
if (counter > winner) { // 값이 초과되면 현재 원소가 당첨자
break; // 당첨자 발견
}
current = current->next;
}
9.5 추첨권 배분 방식
주어진 작업 집합에 대한 추첨권 할당 문제는 미해결 상태
9.6 왜 결정론적(Deterministic) 방법을 사용하지 않는가
무작위성은 정확한 비율을 보장할 수 없기 때문에 결정론적 공정 배분 스케줄러인 보폭 스케줄링(stride scheduling) 고안
보폭 스케줄링
- 각 작업은 보폭을 가지고 있고 추첨권 수에 반비례 함
- ex) 100, 50, 250 추첨권을 가졌고 10000을 각자 추첨권 개수로 나눈다면 보폭은 100, 200, 40
- 프로세스가 실행될 때마다 pass 값을 보폭만큼 증가
- 스케줄링 주기마다 정확한 비율로 CPU 배분
curr = remove_min(queue); // pass 값이 최소인 클라이언트 선택
schedule(curr); // 자원을 타임 퀀텀만큼 프로세스에게 할당
curr->pass += curr->stride; // pass 값을 보폭만큼 증가
insert(queue, curr); // 큐에 다시 저장
세 작업(A, B, C)의 보폭은 각각 100, 200, 40 이고 pass 값은 0에서 시작한다면 위와 같이 동작
하지만 보폭 스케줄링은 상태 정보가 필요한 대신, 추첨 스케줄링은 프로세스 상태(CPU 사용 현황, pass 값) 를 유지할 필요가 없음
따라서 추첨 스케줄링에서는 새 프로세스에 대해 추첨권 개수만 갱신하면 되므로 쉽게 추가가 가능한 장점이 있음
9.7 리눅스 CFS (Completely Faire Scheduler)
Completely Faire Scheduler(CFS, 완전 공정 스케줄러) 의 장점은 효율성과 확장성이다.
최적의 내부 설계와 자료 구조로 신속하게 스케줄링을 결정
기본 연산
CFS 는 고정된 길이의 타임슬라이스를 사용하는 대부분의 기존 스케줄러와 다르다.
CPU 를 공평하게 배분하는 것을 목표로 virtual runtime(vruntime) 이라는 counting 기반 테크닉을 이용한다.
- 실행되는 프로세스의 vruntime 값을 누적시키며, 실제 시간과 같은 속도로 증가
- 가장 낮은 vruntime 을 가진 프로세스를 다음에 실행할 프로세스로 선택
- 자주 실행되면 공정성에 좋지만, 많은 문맥 교환으로 성능 저하 (반대라면 공정성 악화)
- sched_latency: 하나의 프로세스가 CPU 를 사용한 후, 다음 번에 사용할 수 있을 때까지의 최대 시간 간격 (보통 48ms)
- min_granularity: 최소 타임슬라이스, 스케줄링에 많은 시간을 소비하지 않도록 함(보통 6ms)
가중치 (Niceness)
CFS 는 프로세스의 우선 순위를 조정하여 더 많은 CPU 시간을 할당받게 할 수 있다.
nice 레벨이라는 UNIX 메커니즘을 사용하고, 기본 값은 0 이고 범위는 -20 ~ 19 이다.
높을 수록 낮은 우선순위, 낮을 수록 높은 우선순위다.
Red-Black 트리의 활용
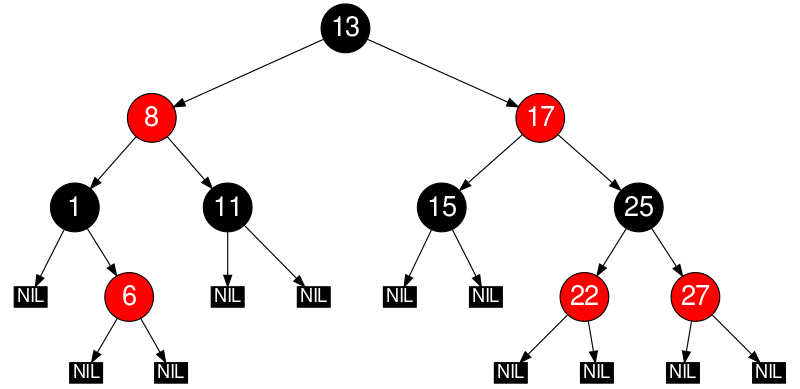
CFS 핵심은 알고리즘 효율성으로 실행할 프로세스를 신속히 선정하는 것이다.
이를 위해 CFS 는 균형 트리의 한 종류인 Red-Black 트리 를 사용한다.
실행 중이거나 실행 가능한 프로세스만 이 구조에 보관하고 sleep 상태가 되면 트리에서 제거하고 다른 곳에 보관한다.
탐색 연산 시간은 O(log n) 이며, 프로세스들은 vruntime 순서대로 트리에 저장되고, 대다수의 연산(삽입, 삭제)은 연산 시간은 O(log n) 이 소요된다.
I/O 와 잠자는 프로세스 다루기
두 프로세스 A와 B 중 A는 계속 실행해오고, B 는 장시간(10초) 있다고 가정한다.
B 가 깨어나면 B의 vruntime 은 A 보다 10초 뒤쳐져 있어서 B는 CPU 를 독점 하게 되고 A는 기아상태에 빠질 수 있다.
CFS 는 이를 해결하기 위해 깨어날 때 vruntime 을 트리에서 찾을 수 있는 가장 작은 값으로 설정한다.
10장. 멀티프로세서 스케줄링(고급)
병행성(concurrency) 주제를 관련하여 멀티프로세서 스케줄링(multiprocessor scheduling) 에 대해 알아본다.
10.1 배경: 멀티프로세서 구조
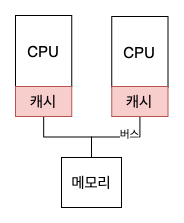
멀티 CPU 하드웨어에서는 다수의 프로세서 간에 데이터 공유, 하드웨어 캐시의 사용 방식에서 차이가 있다.
단일 CPU 시스템에는 프로그램을 빠르게 실행하기 위해 하드웨어 캐시 계층이 존재한다.
캐시는 메인 메모리에서 자주 사용되는 데이터의 복사본을 저장하는 작고 빠른 메모리다.
캐시는 지역성(locality) 에 기반하며, 시간 지역성(temporal locality) 과 공간 지역성(spatial locality) 이 있다.
- 시간적 지역성
- 데이터가 한번 접근되면 가까운 미래에 다시 접근될 가능성이 높음
- 공간적 지역성
- 프로그램이 주소 x 데이터에 접근하면 x 주변의 데이터가 접근될 가능성이 높음
멀티프로세서 시스템 환경에서는 다른 CPU 에서 아직 메인 메모리에 반영되지 않은 값을 가져올 수 있는 캐시 일관성 문제(cache coherence) 가 발생될 수 있다.
이 문제는 하드웨어에서 메모리 주소를 계속 감시하고, 올바른 순서로 처리되도록 관리하면서 해결한다.
버스 기반 시스템에서는 버스 스누핑(bus snooping) 기법을 사용한다.
캐시가 버스의 통신 상황을 모니터링하며, 캐시 데이터에 대한 변경이 발생되면 무효화(invalidate) 하거나 갱신한다.
10.2 동기화를 잊지 마시오
CPU 들이 동일한 데이터에 접근할 때 락과 같은 상호 배제를 보장하는 동기화 기법을 사용한다.
락-프리(lock-free) 데이터 구조 등의 다른 방식은 복잡하고 특별한 경우에만 사용된다.
락(lock) 을 사용하여 올바르게 동작하도록 만들 수 있지만 성능 측면에서는 문제가 있다.
10.3 마지막 문제점: 캐시 친화성
멀티프로세서 캐시 스케줄러의 마지막 문제는 캐시 친화성(cache affinity) 이다.
프로세스가 실행될 때 CPU 캐시와 TLB 에 많은 상태 정보가 있기 때문에 다음에 프로세스가 실행될 때 동일한 CPU 에서 실행되는 것이 유리하다.
10.4 단일 큐 스케줄링
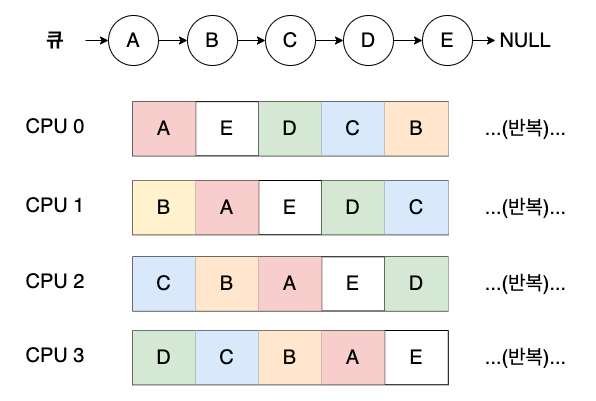
단일 프로세서 스케줄링의 기본 프레임워크를 그대로 사용한 방식이 단일 큐 멀티프로세서 스케줄링(single queue multiprocessor scheduling, SQMS) 이다.
CPU 가 2개라면 실행할 작업 두 개를 선택하는 것이다.
SQMS 장점
- 기존의 단일 CPU 스케줄러가 있다면 구현이 간단
SQMS 단점
- 확장성(scalability) 결여
- 다수의 CPU 에서 동작하기 위해 단일 큐를 접근할 때 올바른 결과가 나오도록 락을 삽입
- 락으로 인해 성능 저하
- 경쟁이 증가할 수록 락에 소모되는 시간이 많아짐
- 다수의 CPU 에서 동작하기 위해 단일 큐를 접근할 때 올바른 결과가 나오도록 락을 삽입
- 캐시 친화성 문제
- 큐에서 다음 작업은 선태갛기 때문에 작업은 CPU 를 옮겨 다니게 됨
- 이 문제를 해결하기 위해 한 프로세스가 동일한 CPU 에서 재실행할 수 있도록 시도
- 구현이 복잡해질 수 있음
10.5 멀티 큐 스케줄링
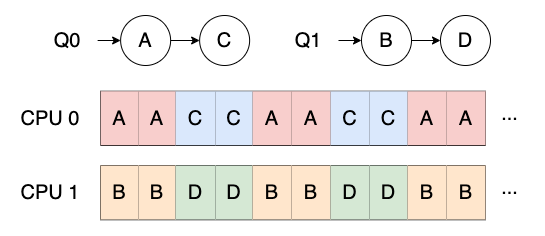
멀티 큐 멀티프로세서 스케줄링(multi-queue multiprocessor scheduling, MQMS) 은 단일 큐 스케줄링 문제 때문에 멀티 큐를 둔 방식이다.
작업이 시스템에 들어가면 하나의 스케줄링 큐에 배치되어 독립적으로 스케줄 된다. (공유 및 동기화 문제 해결)
MQMS 장점
- 확장성이 좋음
- CPU 개수가 증가하면, 큐의 개수도 증가하여 락과 캐시 경합(cache contention) 문제 해결
- 캐시 친화적
- 작업이 같은 CPU 에서 계속 시행
MQMS 단점
- 워크로드의 불균형(load imbalance)
- 한 큐의 작업이 끝났을 경우 CPU 가 놀 수 있음
이주
위 단점을 해결하기 위해 작업을 이동 시키는 기술인 이주(migration) 도입
다양한 이주패턴 중 기본적인 접근 방식은 작업 훔치기(work stealing)
- 작업 훔치기
- 작업의 개수가 낮은 큐가 다른 큐에 작업이 있는지 검사하여 하나이상의 작업을 가져옴
- 큐를 자주 검사하면 높은 오버헤드로 확장성에 문제 발생
- 자주 검사하지 않으면 워크로드 불균형
10.6 Linux 멀티프로세서 스케줄러
멀티 프로세서 스케줄러를 위한 세 가지 스케줄러 등장
- O(1) 스케줄러
- 멀티 큐
- 우선순위 기반 스케줄러
- 상호작용을 우선시 함
- Completely Fair Scheduler(CFS)
- 멀티 큐
- 결정론적(deterministic), 비례배분(proportional share) 방식
- BF 스케줄러(BFS)
- 단일 큐
- 비례배분(proportional share) 방식
11장. CPU 가상화에 관한 마무리 대화
- 가상화를 이해하기 위한 기법
- 트랩
- 트랩 핸들러
- 타이머 인터럽트
- 프로세스 전환 시, 상태 저장 및 복원 방법
- 제한적 직접 실행 (효율적인 실행, 악성 프로세스 제어)
- 스케줄러
- SJF (Short Job First)
- RR (Round Robin)
- MLFQ (Multi Level Feedback Queue)
- CFS (Completely Faire Scheduler)
- BFS (BF Scheduler)
- O(1)