운영체제 아주 쉬운 세가지 이야기 책에 대한 스터디를 진행한다.
이 글에서는 20장부터 24장까지의 내용을 정리한다.
20장. 페이징: 더 작은 테이블
페이징의 두번째 문제는 페이지 테이블의 크기다.
페이지 테이블이 크면 많은 메모리 공간을 차지한다.
20.1 간단한 해법: 더 큰 페이지
페이지 크기를 증가시키면 페이지 테이블의 크기를 줄일 수 있다.
페이지 크기가 4배 증가되면 페이지 테이블의 크기는 1/4로 줄어든다.
하지만 부작용으로 내부 단편화(internal fragmentation) 가 발생한다.
페이지 내부의 낭비 공간이 증가하는 것이다.
할당받은 페이지의 일부분만 사용하게 되기 때문에 메모리가 금방 고갈되는 현상이 발생된다.
20.2 하이브리드 접근 방법: 페이징과 세그멘트
페이징과 세그멘트 방법을 조합하는 것을 하이브리드(hybrid) 라고 한다.
두 방법을 결합하여 테이블 크기를 줄이는 것이다.
프로세스의 전체 주소 공간을 위한 페이지 테이블 대신, 논리 세그멘트마다 따로 페이지 테이블을 둔다.
세그멘테이션은 물리 주속 시작 위치를 나타내는 베이스(base) 레지스터, 크기를 나타내는 바운드(bound) 또는 리미트(limit) 레지스터가 존재한다.
여기서 베이스 레지스터는 세그먼트 시작 주소가 아니라 세그멘트의 페이지 테이블의 시작 주소를 갖는다.
TLB 미스가 발생한 경우 다음과 같이 동작한다. (하드웨어 기반으로 가정)
- 하드웨어가 세그멘트 비트(SN) 을 사용하여 어떤 베이스와 바운드 쌍을 사용할지 결정
- 레지스터에 있는 물리 주소를 VPN과 페이지 테이블 항목(PTE) 주소 획득
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT
VPN = (VirtualAddress & VPN_MASK) >> VPN_SHIFT
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE))
문제점
- 세그멘테이션을 사용
- 빈 공간이 많은 힙의 경우 페이지 테이블의 낭비를 면치 못함
- 외부 단편화 유발
- 페이지 테이블 크기에 제한이 없어 다양한 크기를 가짐
- 메모리상에서 테이블용 공간을 확보하는 것이 복잡
20.3 멀티 레벨 페이지 테이블
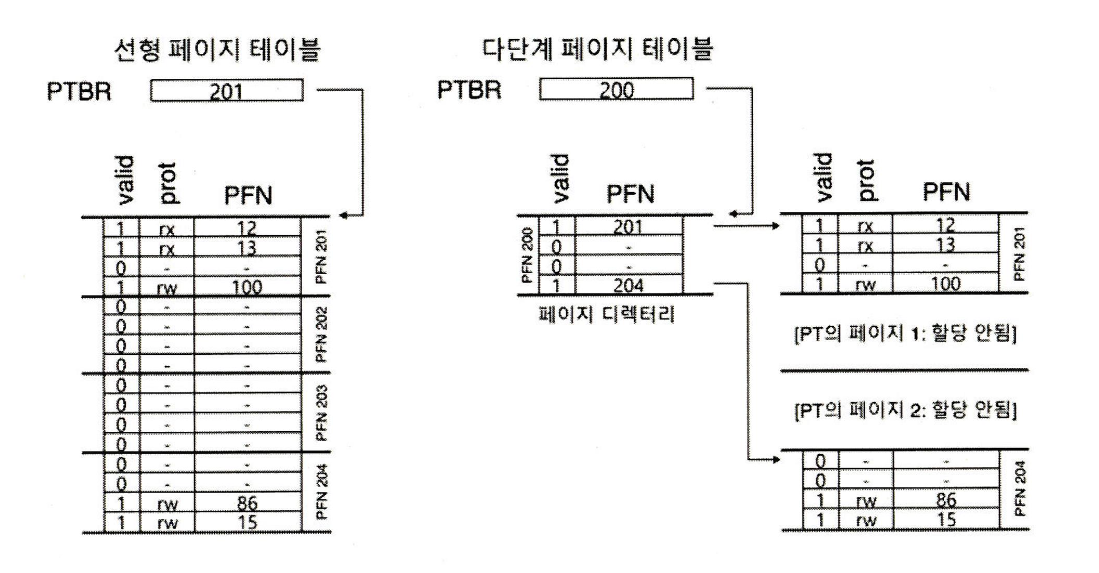
세그멘테이션을 사용하지 않고 페이지 테이블 크기를 줄이는 또 다른 방법은 멀티 레벨 페이지 테이블(multi-level page table) 이다.
멀티 레벨 페이지 테이블에서는 선형 페이지 테이블을 트리 구조로 표현한다.
멀티 레벨 페이지 테이블 개념은 다음과 같다.
- 페이지 테이블을 페이지 크기의 단위로 나눈다.
- 페이지 디렉터리(page directory) 자료 구조로 각 페이지의 할당 여부와 위치 파악
- 페이지 디렉터리에는 페이지 테이블의 구성요소인 각 페이지의 존재 여부와 위치 정보를 가지고 있음
- 페이지 디렉터리는 페이지 디렉터리 항목(page directory entries, PDE) 들로 구성, 페이지 테이블의 한 페이지 표현
- PDE 의 구성은 PTE 와 유사, 유효 비트(valid) 와 페이지 프레임 번호(page frame number, PFN) 를 가짐
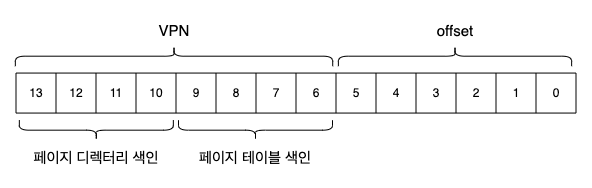
- VPN 에서 페이지-디렉터리 인덱스(page-directory index, PDIndex) 추출하여 PDE 주소 찾음
PDEAddr = PageDirBase + (PDIndex * sizeof(PDE))
- PDE 가 유효하다면 VPN 나머지 주소로 페이지-테이블 인덱스 (page-table index, PTIndex)
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
PhysAddr = (PTE.PFN << SHIFT) + offset- 2단계 이상인 경우 페이지 디렉터리가 추가되면서 가상 주소가 새로운 PD Index 로 추가 분할
장점
- 사용된 주소 공간의 크기에 비례하여 페이지 테이블 공간 할당
- 작은 크기의 페이지 테이블로 주소 공간 표현 가능
- 페이지 테이블을 페이지 크기로 분할하여 메모리 관리 용이
- 페이지 테이블이 산재해 있어도 페이지 디렉터리로 위치 파악이 가능하므로 공간 할당이 유연
문제점
- 추가 비용 발생
- TLB 미스 시, 주소 변환을 위해 두 번의 메모리 로드 발생 (페이지 디렉터리 와 PTE 접근)
- TLB 히트 시 성능은 동일, TLB 미스 시 두 배의 시간 소요
- 복잡도
- 메모리 자원 절약을 위해, 페이지 테이블 검색이 복잡
20.4 역 페이지 테이블
또 다른 공간 절약 방법으로 역 페이지 테이블(inverted page table) 이 존재한다.
여러 개의 페이지 테이블(프로세스당 하나씩) 대신 시스템에 단 하나의 페이지를 두는 것이다.
- 물리 페이지를 가상 주소 상의 페이지로 변환
- 각 항목은 물리 페이지를 사용중인 프로세스 번호, 해당 가상 페이지 번호 를 가지고 있음
- 주소 변환을 위해 전체 테이블 검색
- 탐색 속도 향상을 위해 주로 해시 테이블 사용
20.5 페이지 테이블을 디스크로 스와핑하기
모든 페이지 테이블을 메모리에 상주하기에는 너무 크다.
어떤 시스템들은 페이지 테이블들을 커널 가상 메모리에 위치시키고, 메모리가 부족하면 디스크에 스왑(swap) 한다.
21장. 물리 메모리 크기의 극복: 메커니즘
다수의 프로세스들이 동시에 큰 주소 공간을 사용하는 상황을 가정한다.
이를 위해 메모리 계층에 레이어 추가가 필요하다.
현대 시스템에서는 보통 하드 디스크 드라이브를 큰 주소 공간을 보관해두는 공간으로 사용된다.
편리함과 사용 용이성을 위해 프로세스에게 주소 공간을 충분히 제공해야 한다.
스왑 공간 을 사용하면 프로세스들에게 큰 가상 메모리가 있는 것 같은 환상을 줄 수 있다.
21.1 스왑 공간
스왑 공간(swap space) 은 디스크에 페이지들을 저장할 수 있는 일정 공간이다.
- 스왑 공간의 입출력 단위는 페이지라고 가정
- swap out: 메모리 페이지를 읽어서 스왑 공간에 저장
- swap in: 페이지를 읽어 메모리에 탑재
- 운영체제는 스왑 공간에 있는 모든 페이지들의 디스크 주소 를 저장해야 함
- 스왑 공간을 이용하면, 실제 물리메모리 공간보다 많은 공간이 존재하는 것처럼 가장 가능
- 스왑 공간에만 스왑을 할 수 있는 것은 아님
- 코드 영역의 물리 페이지는 다른 페이지가 사용할 수 있는데 이는 파일 시스템 영역을 스왑 목적으로 사용하는 것임
21.2 Present Bit
하드웨어 기반 TLB 를 사용하는 시스템에서 메모리 참조 과정을 다시 살펴본다.
TLB 히트
- 가상 주소에서 VPN 추출
- TLB 에 정보가 있는지 검사(TLB 히트)
- 물리 주소 얻은 후 메모리로 가져옴
TLB 미스
- 가상 주소에서 VPN 추출
- TLB 에 정보가 있는지 검사(TLB 미스)
- 페이지 테이블의 메모리 주소 파악(페이지 테이블 베이스 레지스터 이용)
- VPN 을 인덱스로 페이지 테이블 항목(PTE) 추출
- 물리메모리에 존재하면 PTE 에서 PFN 정보 추출 후 TLB 탑재
- 명령어 재실행
페이지가 디스크로 스왑되기 위해서 present bit 를 이용하여 PTE 에서 페이지가 물리 메모리에 존재하는지 여부를 표시한다.
1 이라면 물리 메모리에 페이지 존재, 0이면 디스크 어딘가에 존재하는 것이다.
물리 메모리에 존재하지 않는 페이지를 접근하는 행위는 페이지 폴트(page fault) 라고 한다. 페이지 폴트가 발생하면 운영체제로 제어권이 넘어가며 페이지 폴트 핸들러(page-fault handler) 가 실행된다.
21.3 페이지 폴트
페이지 폴트가 발생하면 운영체제의 페이지 폴트 핸들러 가 처리한다.
페이지 폴트 발생 시, 운영체제는 페이지 테이블 항목(PTE) 에서 페이지의 디스크상 위치를 파악하여, 메모리로 탑재한다.
- 디스크 I/O 가 완료되면 운영체제는 PTE 의 PFN 값을 탑재된 페이지의 메모리 위치로 갱신
- 페이지 폴트를 발생시킨 명령어 재실행
- 재실행으로 인해 TLB 미스가 발생되면 TLB 미스 처리 과정이후 TLB 값 갱신(페이지 폴트 처리시 함께 갱신도 가능)
- 재실행 시에 TLB 에서 주소 변환 정보 찾고 물리 주소에서 데이터 가져옴
I/O 실행은 시간이 많이 소요되므로 프로세스는 차단된(blocked) 상태가 된다.
멀티 프로그램된 시스템에서는 다른 프로세스의 실행을 중첩(overlap) 시킬 수 있다.
21.4 메모리에 빈 공간이 없으면?
스왑 공간으로부터 페이지를 가져오기 위한 (page-in) 여유 메모리가 부족하면, 다른 페이지들을 먼저 페이지 아웃(page-out) 할 수 있다.
교체(replace) 페이지를 선택하는 것이 페이지 교체 정책(page-replacement policy) 라고 한다.
21.5 페이지 폴트의 처리
- 탑재할 페이지를 위한 물리 프레임 확보
- 여유 프레임이 없으면 교체 알고리즘으로 페이지 아웃(page-out) 으로 여유 공간 확보
- I/O 요청ㅇ로 스왑 영역에서 페이지 읽어옴
- 페이지 테이블을 갱신하고 명령어 재실행
- 재실행하면 TLB 미스가 발생하며, 다시 재시도할 때 TLB 히트
21.6 교체는 실제 언제 일어나는가
교체 알고리즘은 효율적이지 않기 때문에 운영체제는 항상 여유 메모리 공간을 확보하고 있어야 한다.
그래서 대부분의 운영체제들은 여유 공간에 관련된 최댓값(high watermark, HW) 과 최솟값(low watermark, LW) 을 설정하여 교체 알고리즘 작동에 활용한다.
여유 공간의 크기가 최솟값보다 작아지면 여유 공간 확보를 위한 백그라운드 쓰레드가 최댓값에 이를 때까지 페이지를 제거한다.
백그라운드 쓰레드는 스왑 데몬(swap daemon) 또는 페이지 데몬(page daemon) 이라고 불린다.
많은 시스템들은 성능을 높이기 위해 페이지들을 클러스터(cluster) 나 그룹(group) 으로 묶어 스왑 파티션에 저장하여 디스크의 효율을 높인다.
22장. 물리 메모리 크기의 극복: 정책
운영체제는 빈 메모리 공간이 부족해서 메모리 압박(memory pressure) 을 받으면 강제적으로 페이징 아웃(paging out) 을 수행한다.
내보낼(evict) 페이지 선택은 페이지 교체 정책에 의해 결정된다.
22.1 캐시 관리
캐시를 위한 교체 정책의 목표는 캐시 미스를 최소화, 캐시 히트를 최대화하는 것이다.
캐시 히트와 미스 횟수를 알면 평균 메모리 접근 시간(average memory access time, AMAT) 을 계산할 수 있다.
AMAT = TM + (PMiss * TD)
- TM : 메모리 접근 비용
- TD : 디스크 접근 비용
- PMiss : 캐시 미스 확률
22.2 최적 교체 정책
교체 정책을 이해하기 위해서는 최적 교체 정책(The Optimal Replacement Policy) 을 아는 것이 좋다.
최적 교체 정책은 가장 나중에 접근될 페이지를 교체하여 미스를 최소화 한다.
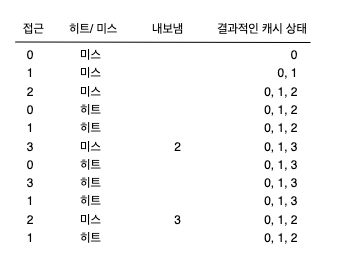
캐시가 비워진 상태이기 때문에 첫 세 번은 미스가 발생된다.
이러한 미스는 최초 시작 미스(cold start miss) 또는 강제 미스(compulsory miss) 라고 한다.
그리고 현재 탑재되어 있는 페이지들 미래를 살펴보고 먼 미래에 접근될 페이지를 내보낸다.
하지만 일반적으로 미래는 알 수 없기 때문에 최적 기법의 구현은 불가능 하다.
22.3 간단한 정책: FIFO
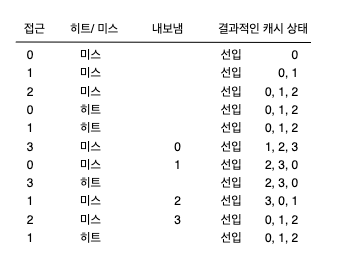
FIFO 교체 방식에서 페이지가 시스템에 들어오면 큐에 삽입되고, 교체를 해야할 경우 큐의 테일에 있는 페이지가 내보내진다.
FIFO 교체 방식은 구현이 쉽지만 성능이 안좋다.
22.4 또 다른 간단한 정책: 무작위 선택
이 방식은 무작위로 선택하여 교체하는 방식이다.
구현은 쉽지만 내보낼 페이지가 제대로 선택되지 않을 수 있다.
무작위 선택 방식의 성능은 그때그때 달라진다.
22.5 과거 정보의 사용: LRU
페이지 교체 정책이 활용될 수 있는 페이지의 정보는 빈도수(frequency) 와 최근성(recency) 가 있다.
지역성의 원칙(principle of locality) 에 따르면 최근에 접근된 페이지일수록 다시 접근될 확률이 높다.
그래서 과거 이력을 기반한 다음과 같은 교체 알고리즘들이 존재한다.
- Least-Frequently-Used(LFU) : 가장 적은 빈도로 사용된 페이지 교체
- Least-Recently-Used(LRU) : 가장 오래 전에 사용됐던 페이지 교체
이와 반대인 정책도 존재하지만 지역성 접근 특성을 무시하기 때문에 잘 동작하지 않는다.
- Most-Frequently-Used(MFU) : 가장 많은 빈도로 사용된 페이지 교체
- Most-Recently-Used(MRU) : 가장 최근에 사용된 페이지 교체
22.6 워크로드에 따른 성능 비교
- 지역성이 없다면 어느 정책을 사용하든 상관 없음
- LRU, FIFO, 무작용 선택 모두 비슷한 성능을 보임
- 캐시가 충분히 커서 모든 워크로드를 포함할 수 있다면 어느 정책을 사용하든 상관 없음
- 모든 블럭들이 캐시에 들어갈 수 있으면 히트율이 100%
-
최적 기법이 다른 정책들보다 좋은 성능을 보임
- 80대 20 워크로드 인 경우 (20% 페이지들에서 80% 참조, 80% 페이지들에서 20% 참조)
- 최적 기법 > LRU > FIFO 순서로 좋은 성능을 보임
- 순차 반복 워크로드인 경우 (여러 페이지들을 순차적으로 참조)
- 오래된 페이지들을 내보내기 때문에 LRU 와 FIFO 정책에서 가장 안좋은 성능을 보임
- 무작위 선택 정책은 최적 기법보다 미치지는 못하지만 좋은 성능
22.7 과거 이력 기반 알고리즘 구현
과거 정보에 기반은 둔 정책을 구현하기 위해서는 많은 작업이 필요하다.
어떤 페이지가 가장 최근 또는 오래 전에 사용됐는지 참조 정보 기록이 필요하지만, 기록에 주의하지 않으면 성능이 떨어질 수 있다.
시스템 페이지 수가 증가하면 가장 오래전에 사용된 페이지를 찾는데 고비용 연산이 된다.
가장 오래된 페이지가 아닌 비슷하게 오래된 페이지를 찾는 방법을 고민해본다.
22.8 LRU 정책 근사하기
LRU 를 근사하는 식으로 만들면 구현이 쉬워진다.
이를 위해 use bit(또는 reference bit) 가 필요하다.
각 페이지 마다 하나의 use bit 가 있으며 페이지가 참조될 때마다 1로 설정된다.
use bit 를 활용하는 방법들에 대해 알아본다.
- 시계 알고리즘(clock algorithm)
- 모든 페이지들이 환형 리스트로 구성한다고 가정
- 시계 바늘 (clock hand) 이 특정 페이지를 가리킴
- 페이지를 교체해야할 때 현재 바늘이 가리키는 페이지의 use bit 검사
- 1이라면 최근에 사용된 것이므로 교체 대상이 아니면서 use bit 를 0으로 설정
- 시계 바늘은 P+1 로 이동
- 0으로 설정된 페이지를 찾을 때까지 반복
- Corbato 알고리즘
- 미사용 페이지를 찾기 위해 모든 메모리를 검사하지 않아도 되는 특성을 지님
- 변형된 시계 알고리즘
- 교체할 때 페이지들을 랜덤하게 검사
- 탐색 내성(scan resistance)
- 대개 LRU와 동작은 유사하지만 최악의 경우에 보이는 행동을 방지
22.9 갱신된 페이지(Dirty Page)의 고려
페이지가 변경(modified) 되어 더티(dirty) 상태가 되었다면,
디스크에 기록해야하기 때문에 비용이 많이 든다.
이러한 이유로 페이지를 내보낼 때 더티 페이지보다 깨끗한 페이지 를 교체하는 것을 선호한다.
변경 여부를 판단하기 위해 하드웨어는 modified bit(더티 비트) 를 포함한다.
페이지가 변경되면 이 비트가 1로 설정되는데 이를 고려하여 교체 대상이 선택된다.
22.10 다른 VM 정책들
페이지 교체 정책만이 유일한 정책이 아니다.
- 페이지 선택(page selection) 정책
- 언제 페이지를 메모리로 불러들일지 결정
- 요구 페이징(demand paging) 정책
- 페이지가 실제 접근될 때 해당 페이지를 메모리로 읽어 들임
- 어떤 페이지가 사용될지 예상하여 미리 읽어 들일 수도 있음 (선반입(prefetching))
- 클러스터링(clustering) 또는 쓰기 모으기(grouping or write)
- 기록해야 할 페이지들을 메모리에 모은 후 한번에 기록하는 방식
- 디스크 드라이브는 여러 개 작은 크기보다 하나의 큰 쓰기 요청이 더 효율적임
22.11 쓰레싱(Thrashing)
실행 중인 프로세스가 가용 물리 메모리 크기를 초과하면 시스템은 끊임없이 페이징을 한다.
이러한 상황을 쓰래싱(thrashing) 이라고 한다.
운영체제들에는 쓰래싱이 발생했을 때 발견과 해결을 위한 기법들이 존재한다.
- 일부 프로세스를 중지하여 나머지 프로세스를 탑재
- 프로세스가 일정 시간동안 사용하는 페이지들의 집합을 워킹 셋(working set) 이라고 하며, 진입 제어(admission control) 방법을 활용
- 많은 일을 엉성하게 하는 것보다 적은 일을 제대로 하는 것이 나음
- 메모리 부족 킬러(out-of-memory killer) 실행
- 많은 메모리를 요구하는 프로세스를 골라 죽임
23장. 완전한 가상 메모리 시스템
완전한 가상 메모리 시스템을 구현하기 위해서는 성능, 기능성, 및 보안을 위한 다양한 특징들이 필요하다.
다음 두 개의 시스템을 살펴보면서 구현 방법에 대해 알아본다.
- VAX/VMS
- Linux 의 가상 메모리 시스템
23.1 VAX/VMS 가상 메모리
VAX/VMS 운영체제는 다양한 종류의 시스템에서 동작하는 기법과 정책들이 필요했다.
VMS 는 컴퓨터의 구조적 결함을 소트르웨어로 보완한 훌륭한 사례다.
메모리 관리 하드웨어
VAX-11 은 프로세스마다 512바이트 페이지 단위로 나누어진 32비트 가상 주소 공간(가상 주소 23비트, 9비트 오프셋)을 제공한다.
페이징과 세그멘테이션의 하이브리드 구조를 가지고 있다.
프로세스 공간의 첫 번째 절반(P0)은 사용자 프로그램과 힙(heap)이 존재 (주소가 큰쪽으로 증가)
두 번째, 큰 쪽 절반은(P1) 주소가 스택(stack) 존재(주소가 작은 방향으로 증가)
주소 공간의 상위 절반은 반만 사용되며 시스템 공간 (보호된 코드와 데이터 존재)
하지만 VMS 에는 페이지 테이블의 크기가 512바이트로 커진다는 문제가 있었다.
이 메모리 압박 정도를 경감시키기 위해 두 가지 방법을 사용했다.
- 사용자 주소공간을 두 개의 세그멘트로 나누어 프로세스마다 (P0 과 P1) 각 영역을 위한 페이지 테이블 소유
- 스택과 힙 사이의 사용되지 않는 주소 영역을 위한 페이지 테이블 공간이 필요 없음
- 사용자 페이지 테이블들을 커널의 가상 메모리에 배치
- 메모리 공간이 부족하면 페이지 테이블들을 디스크로 스왑하여 메모리 확보
실제 주소 공간
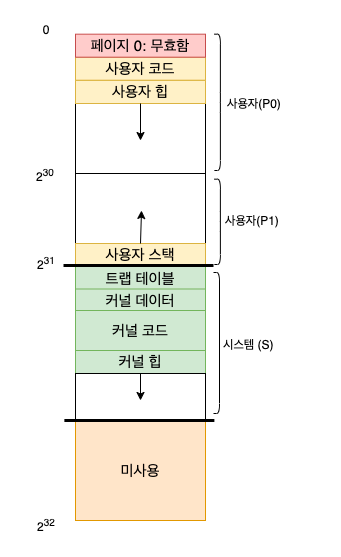
- 코드 세그먼트는 절대 페이지 0에서 시작하지 않음 (접근 불가능한 페이지로 마킹)
- 커널의 가상 주소 공간은 사용자 주소 공간의 일부
- 문맥 교환이 발생되면 P0과 P1 레지스터를 다음 실행될 프로세스의 페이지 테이블을 가리킴
- s 베이스와 바운드 레지스터는 변경되지 않기 때문에 동일한 커널 구조들이 사용자 주소 공간에 매핑
- 운영체제는 응용 프로그램이 운용체제의 데이터나 코드를 읽거나 쓰는 것을 보호
- 커널은 사용자 프로세스가 커널의 데이터를 읽거나 쓰는 것을 보호
- protection bit 에 보호 수준을 지정하여 권한 수준을 기록
- 보호 수준의 자료를 접근하면 트랩이 걸리고 프로세스는 종료됨
페이지 교체
VAX 페이지 테이블 항목(PTE) 는 다음과 같은 비트들을 가지고 있음
- 유효 (valid) 비트
- 보호 필드(protection field, 4비트)
- 변경(modify) 또는 더티(dirty) 비트
- 운영체제가 예약해 놓은 필드(5비트)
- 물리 프레임 번호(PFN)
참조 비트(reference bit) 는 포함되지 않은 문제와 메모리 호그(memory hog) 에 대한 문제를 해결하기 위해 세그멘트된 FIFO 교체 정책을 제안했다.
메모리 호그(memory hog): 메모리를 너무 많이 사용하는 프로그램
세그멘트된 FIFO 교체 정책은 다음과 같다.
- 각 프로세스는 상주 집합 크기 (resident set size, RSS) 라는 메모리에 유지할 수 있는 최대 페이지 개수를 지정
- 페이지들은 FIFO 리스트에 보관
- 페이지 개수가 RSS 보다 커지면 먼저 들어온 페이지가 아웃
FIFO의 성능을 개선하기 위한 방법으로는 다음과 같다.
- 클린-페이지 프리 리스트와 더티 페이지 리스트라는 second-chance list 도입
- second-chance list 는 메모리에서 제거되기 전에 페이지가 보관되는 리스트
- 제거된 페이지가 수정 안된 상태라면 클린-페이지 프리 리스트, 변경된 상태라면 더티 페이지 리스트
- VMS의 작은 페이지 크기 극복
- 페이지 크기가 작을 수록 스왑할 때 디스크 I/O가 비효율
- 클러스터링(clustering) 기법으로 작업 묶음을 만들어 한번에 디스크로 보냄
그외 기법들
VMS 는 표준화된 게르은(lazy) 최적화 기법 두 가지가 더 있다.
- 요청 시 0으로 채우기(demand zeroing)
- 페이지 추가 요청이 오면 페이지를 찾아 0으로 채움(이전에 사용했던 페이지의 내용을 볼 수 없도록 보안을 위함)
- 해당 페이지를 사용하지 않는다면 많은 비용을 지불하게 됨
- 물리 페이지를 0으로 채우고 프로세스 주소 공간으로 매핑하는 작업이 필요 없어짐
- 쓰기-시-복사(copy-on-write, COW)
- 한 주소 공간에서 다른 공간으로 페이지 복사가 필요하다면, 복사하지 않고 해당 페이지를 대상 주소 공간으로 매핑
- 페이지 테이블 엔트리를 양쪽 주소 공간에서 읽기 전용으로 표시
- 데이터 이동없이 빠른 복사 가능
- 쓰기를 시도하면 트랩이 발생되면서 페이지 할당 및 데이터로 채우고 주소 공간에 매핑
- 메모리 공간 절약 가능
23.2 Linux 가상 메모리 시스템
가장 많은 수를 차지하고 있는 Intel x86 용 Linux 를 대상으로 살펴본다.
Linux 주소 공간
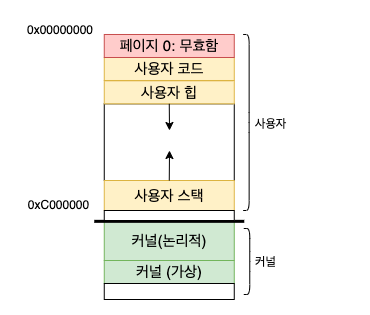
Linux 가상 주소는 다음과 같이 구성된다.
- 사용자 영역: 사용자 프로그램 코드, 스택, 힙 및 기타 부분이 탑재되는 부분
- 커널 영역: 커널 코드, 스택, 힙 및 기타 부분이 탑재되는 부분
문맥 교시 현재 실행중인 주소 공간의 사용자 영역이 변경된다.
사용자 모드에서 실행되는 프로그램은 커널로 트랩이 발생하고 특권 모드로 전환되어야 커널 메모리에 접근 가능하다.
Linux 는 커널 가상 주소의 유형이 두 개다.
- 커널 논리 주소(kernel logical address)
- 커널의 가상 주소 공간 (페이지 테이블, 프로스세스 별 커널 스택 등)
- 이 유형의 메모리가 더 필요하면
kmalloc호출 - 디스크로 스왑 불가능
- 커널 논리 주소는 물리 메모리의 첫 부분에 직접 매핑
- 커널 논리 주소와 물리 주소 사이의 변환이 간단
- 메모리 청크가 논리 주소 공간에서 연속적이면 물리 메모리에서도 연속적이므로 DMA 에 적합
- 커널 가상 주소(kernel virtual address)
- 이 유형의 메모리가 필요하면
vmalloc호출 - 연속적이지 않게 물리 페이지에 매핑 될 수 있으므로 DMA 적합하지 않음
- 더 쉽게 할당할 수 있어서 연속된 물리 메모리 청크는 찾는 것이 어려운 대용량 버퍼 할당에 사용
- 이 유형의 메모리가 필요하면
DMA: 직접 메모리 접근 방식 (direct memory access)
페이지 테이블 구조
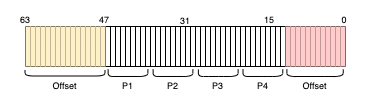
- x86은 다중 레벨 페이지 테이블을 사용
- 전체 64비트 시스템은 4레벨 테이블 사용
- 가상 주소 상위 16 비트는 사용되지 않음 (역할이 없음)
- 하위 12비트가 오프셋으로 사용
- 변환에는 중간의 36비트가 관여
- 시스템 메모리가 커지면 페이지 테이블 트리 구조의 레벨이 증가
크기가 큰 페이지 지원
Intel x86은 여러 페이지 크기를 사용할 수 있다.
거대한 페이지를 사용하면 다음과 같은 장점이 존재한다.
- 페이지 테이블에 필요한 매핑 개수 감소
- TLB가 더 효과적으로 작동하고 성능 향상
- TLB가 변환 결과로 빨리 채워지게 됨
- 거대한 페이지는 TLB의 적은 슬롯을 사용해도 TLB 미스 없이 큰 메모리 공간에 접근 가능
- TLB 미스가 발생 했을 때 할당이 빠르게 처리됨
TBL 를 더 효과적으로 사용하기 위해 투명한(transparent) 거대한 페이지 지원 추가했다.
이 기능은 응용프로그램을 수정하지 않아도 거대한 페이지를 할당할 수 있는 기회를 자동으로 찾는다.
하지만 거대한 페이지를 사용하는 것에는 단점도 존재한다.
- 내부 단편화(internal fragmentation)
- 사용되지 않는 페이지들로 메모리를 채울 수 ㅣㅇㅆ음
- 거대한 페이지를 사용하면 스와핑도 작동하지 않으며 시스템의 I/O 양을 증가 시킴
페이지 캐시
대부분의 시스템은 영구 저장장치 접근 비용을 줄이기 위해 캐싱 서브시스템을 사용한다.
Linux 페이지 캐시(page cache) 는 세 가지 주요 소스로부터 온 페이지를 메모리에 유지할 수 있도록 통합한다.
이러한 요소들은 페이지 캐시 해시 테이블(page cache hash table)에 저장되어 빠른 검색이 가능하다.
- 메모리 맵 파일(memory-mapped file)
- 파일 데이터와 장치의 메타 데이터 (
read()와write()호출되어 액세스) - 힙과 각 프로세스를 구성하는 스택 페이지 (공급 파일은 없고 스왑 공간이 데이터를 공급하기때문에 anonymous memory 라고도 함)
페이지 캐시는 항목이 클린 또는 더티인지 추적하고,
더티 데이터라면 백그라운드 쓰레드에 의해 주기적으로 영구 저장 장치에 다시 기록된다.
리눅스에서는 메모리 확보를 위해 2Q 교체 알고리즘을 사용하여 축출할 페이지를 결정한다.
두 개의 리스트를 유지하여 메모리를 두 부분으로 나누어 관리한다.
처음 액세스 되면 비활동 리스트(inactive list) 에 저장되고, 다시 참조되면 활동 리스트(active list) 로 이동한다.
교체 후보는 inactive list 에서 선택되며, 주기적으로 active list 의 맨 아래 페이지를 inactive list 이동시킨다.
Linux 는 LRU 순서가 되도록 이 리스트를 관리하려고 했지만 비용이 많이 을어 LRU 근사 알고리즘(클록 교체 알고리즘과 유사)을 사용
보안과 버퍼 오버플로 공격
버퍼 오버 플로(buffer overflow) 공격은 공격자가 버퍼의 경계를 넘도록 데이터를 길게 입력하여 목표 메모리를 덮어쓰며 발생되는 버그를 찾는 것이다.
이 공격 으로 프로그램이나 커널 자체를 대상으로 사용될 수 있다.
공격이 성공하면 권한 상승(privilege escalation) 되어 많은 자원에 접근이 가능하다.
방어 방법으로는 특정 영역에 탑재된 코드를 실행할 수 없게 만드는 것이다. (NX 비트(No-eXecute))
하지만 공격자는 코드를 주입할 수 없을 때에도 ROP(return-oriented programming) 형태로 임의의 명령 시퀀스를 실행할 수 있다.
공격자는 실행 중인 함수의 복귀 주소가 악성 명령어를 가리키게끔 스택을 덮어써서 가젯(gadgets) 으로 원하는 코드를 실행할 수 있다.
ROP를 방어하기 위해 ASLR(address space layout randomization) 를 추가한다.
가상 주소 공간내에 코드, 스택 및 힙을 무작위로 배치하는 것이다.
다른 보안 관련 문제들: Meltdown And Spectre
CPU 가 성능을 향상 시키기위해 speculative execution 이라는 기법을 사용하면서 이 문제의 핵심이 된다.
이 기법은 향후 실행될 명령을 추측하고 미리 실행하는 기법이다.
예측하기 위해 실행 흔적을 남기기 때문에 취약하게 될 수 있는 것이다.
커널 보호를 강화하기 위해서 커널 주소 공간을 많이 제거하고 커널 데이터에 대해 커널 페이지 테이블을 사용하는 것이다.
이러한 방법을 커널 페이지 테이블 격리(kernel page table isolation, KPTI) 라고 한다.
24장. 메모리 가상화를 정리하는 대화
- 프로세스의 명령어 반입, 명시적인 로드와 스토어 동작 방식 이해
- 프로그램 내에서 볼 수 있는 주소는 가상 주소
- 데이터와 코드가 메모리에 있는 것 같은 환상을 만들어 냄
- 주소 변환을 위해 적은 하드웨어 캐시를 갖는 시스템을 지원하는 TLB
- TLB 로 인해 가상 주소를 물리 주소로 변환하는 과정을 빠르게 할 수 있음
- 페이지 테이블은 크기 때문에 크고 느린 메모리에 존재
- 페이지 테이블은 배열과 같은 자료구조 부터 멀티 레벨 테이블로 발전
- 주소 변환 구조는 필요할 때만 공간을 생성할 수 있도록 유연해야 함 (ex. 멀티레벨 테이블)
- 페이지 교체 정책