운영체제 아주 쉬운 세가지 이야기 책에 대한 스터디를 진행한다.
이 글에서는 영속성에 대해 다룬 35장부터 40장까지의 내용을 정리한다.
35장. 영속성에 관한 대화
컴퓨터가 멈추고 디스크가 고장나고 전원이 꺼져도 정보를 그대로 유지해야 한다.
36장. I/O 장치
입력/출력 장치(I/O) 의 개념과 이 장치가 운영체제와 상호 작용하는 방법을 알아본다.
36.1 시스템 구조
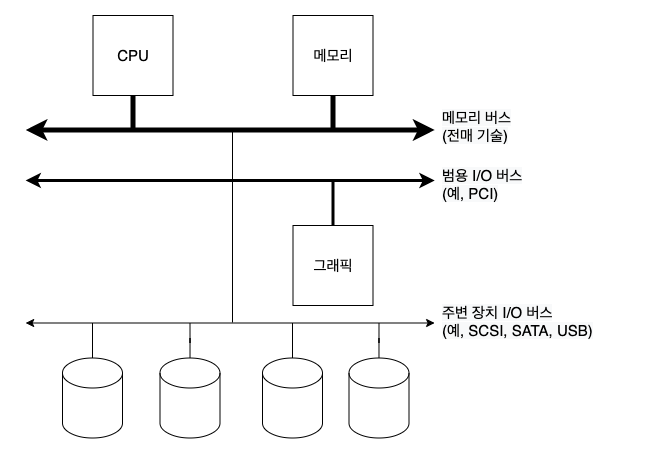
CPU 와 주메모리는 메모리 버스로 연결되어 있다.
몇몇 장치들은 범용 I/O 버스 에 연결되어 있는데, 현대 시스템에서는 PCI 를 사용한다.
그 아래에는 SCSI, SATA(Serial ATA), USB 와 같은 주변 장치용 버스 가 있고 이를 통해 디스크, 마우스, 키보드 같은 장치가 연결된다.
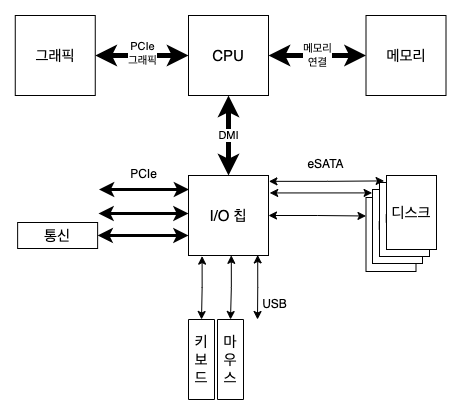
현대식 시스템은 칩셋들과 점대점 연결 방식을 늘리고 있다.
- DMI(Direct Media Interface)
- CPU가 이 기술로 I/O 칩에 연결
- eSATA(external SATA)
- 하드 디스크들이 연결
- ATA(AT attachment, 고급 기술 결합)
- SATA(Serial ATA)
- PCIe(Peripheral Component Interconnect Express, 주변 장치 연결 익스프레스)
36.2 표준 장치
가상의 표준 장치를 효율적 활용하기 위한 두 가지 요소가 있다.
- 하드웨어 인터페이스 (레지스터 상태, 명령, 데이터)
- 인터페이스를 제공하여 시스템 소프트웨어가 동작을 제어할 수 있도록 해야 함
- 내부 구조(CPU, 메모리, 하드웨어에 특화된 칩)
- 장치의 기능을 추상화하여 시스템 제공하에 목적에 맞게 동작 해야 함
36.3 표준 방식
장치의 인터페이스는 세 개의 레지스터로 구성되어 있다.
- 상태(status) 레지스터
- 장치의 현재 상태를 읽음
- 명령(command) 레지스터
- 장치가 데이터를 보내거나 받거나 할 때 사용
- 데이터(data) 레지스터
- 장치에 데이터를 보내거나 받거나 할 때 사용
장치가 동작을 할 때 다음과 같은 방식을 따른다.
While (STATUS == BUSY)
; // 장치가 바쁜 상태가 아닐 때까지 대기
데이터를 DATA 레지스터에 쓰기
명령어를 COMMAND 레지스터에 쓰기 (장치가 명령어 실행)
While (STATUS == BUSY)
; // 요청을 완료할 때까지 대기
- 반복적으로 상태 레지스터를 읽어서 명령의 수신 여부 판단 (polling 방식, 비효율적)
- 운영체제가 데이터 레지스터에 데이터 전달 (데이터 전송에 메인 CPU 가 관여하게 되면 programmed I/O 라고 함)
- 운영체제가 명령 레지스터에 명령어 기록
- 디바이스가 처리 완료되었는지 폴링하면서 대기
36.4 인터럽트를 이용한 CPU 오버헤드 개선
폴링 대신 입출력 작업을 요청한 프로세스를 블록시키고 CPU 를 다른 프로세스에게 양도한다.
장치가 작업을 끝마치고 나면 하드웨어 인터럽트를 발생시키고
CPU 는 인터럽트 서비스 루틴(interrupt service routine, ISR) 또는 인터럽트 핸들러(interrupt handler) 를 실행한다.
단점
- 문맥 교환 비용 또한 비싸기 때문에 폴링이 빠른 장치라면 폴링 방식이 더 좋을 수 있음
- 장치 속도를 모른다면 짧은 시간동안만 폴링 하다가 인터럽트를 사용하는 하이브리드 방식 을 사용하는 것이 좋음
- 인터럽트만 처리하다가 프로세스 요청을 처리할 수 없도록 무한반복(livelock) 에 빠질 수 있음
- 폴링을 사용하면 보다 효율적으로 제어할 수 있음
- 병합(coalescing) 기법으로 잠시 기다렸다가 한번만 인터럽트를 발생시키는 방법으로 처리할 수 있음
36.5 DMA를 이용한 효율적인 데이터 이동
많은 양의 데이터를 디스크로 전달하기 위해 prodgrammed I/O(PIO) 를 사용하면 CPU 를 이용하기 때문에 비효율적이다.
직접 메모리 접근 방식(Direct Memory Access, DMA) 을 사용하면 CPU 간섭없이 메모리와 장치 간에 전송할 수 있다.
동작 과정
- 데이터를 장치로 전송한다고 하면 DMA 엔진에 메모리상의 데이터 위치와 전송할 데이터의 크기와 대상 장치를 프로그램
- 이 시점에 운영체제는 다른 작업을 수행
- DMA 동작이 끝나면 DMA 컨트롤러가 인터럽트를 발생시켜 완료되었다고 알림
36.6 디바이스와 상호작용하는 방법
장치와 운영체제가 정보를 교환하는 기본적인 방법 두 가지를 알아본다.
- I/O 명령을 명시적으로 사용
- 운영체제가 특정 장치 레지스터에 데이터 전송할 수 있음
- 대부분이 특권(privileged) 명령어 운영체제가 장치를 제어
- 맵 입출력(memory mapped I/O)
- 장치의 레지스터들이 메모리 상에 존재하는 것처럼 만듦
- load/store 명령어가 주 메모리 대신 장치로 연결되도록 함
36.7 운영체제에 연결하기: 디바이스 드라이버
서로 다른 인터페이스를 가진 장치들과 운영체제를 연결시키는 방법으로 추상화(abstraction) 가 있다.
- 디바이스 드라이버(device driver)
- 장치의 동작 방식을 알고 있는 운영체제 최하위 계층의 일부 소프트웨어
- 자세한 상호작용은 내부에 있음
- 어떤 장치에도 필요하기 때문에 커널 코드의 대부분을 차지함
- 특정 장치의 특별한 기능을 사용할 수 없을 수 있음
37장. 하드 디스크 드라이브
시스템의 영구적인 데이터 저장소로 사용되는 하드 디스크 드라이브에 대해 알아본다.
37.1 인터페이스
드라이브는 읽고 쓸 수 있는 많은 수의 섹터(512byte 블럭)들로 이루어져있다.
그래서 디스크를 섹터들의 배열로 볼 수 있으며 드라이브의 주소 공간이 된다.
많은 파일 시스템들은 한번에 4KB 를 읽거나 쓸 수 있지만, 드라이브는 512byte 쓰기만 원자성 을 보장하기 때문에 일부만 작성될 수 있다. (찢어 쓰기(torn write))
37.2 기본 구조
- 플래터(platter)
- 원형의 딱딱한 표면
- 자기적 성질을 변형하여 데이터 지속
- 디스크는 하나 또는 여러 개의 플래터를 갖고 있으며 각각은 2개의 표면(surface) 를 가짐
- 회전축(spindle)
- 플래터들을 고정
- 모터와 연결되어 있어서 플래터를 회전
- 분당 회전수(rotation per minute, RPM) 로 측정 되며 보통 7,200 ~ 15,000RPM
- 트랙(track)
- 표면에 동심원을 따라 섹터들 위에 데이터가 부호화되는데 이 동심원 하나를 트랙이라고 함
- 표면에 트랙들이촘촘하게 붙어 있음
- 디스크 헤드(disk head)
- 디스크의 자기적 패턴을 감지하거나 변형을 유도하는 장치
- 디스크 암(disk arm)
- 디스크 헤드를 트랙 위로 움직이는 장치
37.3 간단한 디스크 드라이브
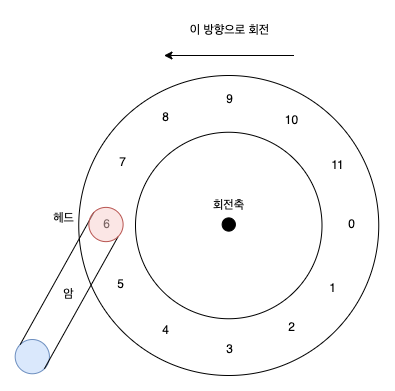
이 트랙에는 12개의 섹터가 있고 각 섹터는 512 byte 크기를 갖고 있다.
주소 영역은 0 부터 11까지(0 ~ n-1)로 이루어져 있다.
단일 트랙 지연 시간: 회전 지연
회전형 지연(rotational delay) 또는 회전 지연(rotation delay) 은 디스크 헤드 아래에 원하는 섹터가 위치할 때까지 기다리는 것을 의미한다.
멀티 트랙: 탐색 시간
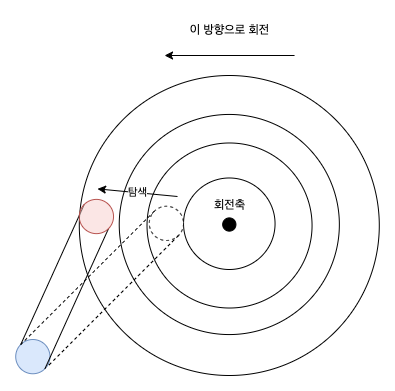
탐색(seek) 은 읽기 요청을 처리하기 위해 드라이브를 디스크 암을 올바른 트랙 위에 위치시키는 과정니다. 탐색은 여러 단계로 이루어져 있다.
- 가속 단계: 디스크의 암이 움직이기 시작
- 활주 단계: 디스크 암이 최고 속도로 움직이는 단계
- 감속 단계: 디스크 암의 속도가 줄어드는 단계
- 안정화 단계: 정확한 트랙 위에 위치하는 단계 (안정화 시간(settling time) 이 중요, 보통 0.5 ~ 2msec)
그 외의 세부사항
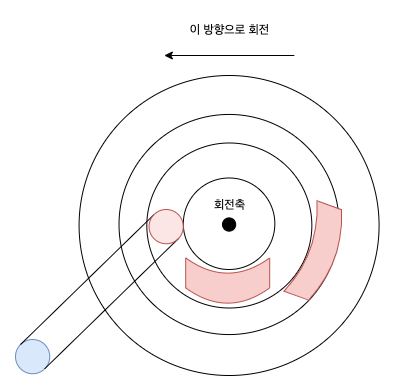
- 트랙 비틀림(track skew)
- 트랙의 경계를 지나 순차적으로 존재하는 섹터들을 읽을 수 있는 기술
- 트랙으로 넘어갈 때 읽어야 할 블럭을 놓치지 않고 읽을 수 있음
- 멀티 구역(multi-zoned)
- 디스크 드라이브는 바깥 측 트랙들이 안쪽 트랙들보다 많은 섹터들이 있는 트랙
- 여러 구역으로 나뉘어 있으며 한 구역은 연속적으로 존재하는 트랙들의 집합
- 각 구역 내의 트랙은 같은 수의 섹터들을 포함하고 있음
- 캐시(cache) 또는 트랙 버퍼(track buffer)
- 일반적으로 8 또는 16MB 정도 크기의 메모리
- 드라이브가 디스크에서 읽거나 쓴 데이터를 보관하는 데 사용
- 쓰기 요청의 완료 보고
- write-back 캐싱(즉시 보고(immediate reporting)): 메모리에 데이터가 기록된 시점에 쓰기가 완료되었다고 보고
- 빠르게 보일 수 있지만 위험할 수 있음
- write-through: 디스크에 실제로 기록된 시점에 쓰기가 완료되었다고 보고
- write-back 캐싱(즉시 보고(immediate reporting)): 메모리에 데이터가 기록된 시점에 쓰기가 완료되었다고 보고
37.4 I/O 시간 계산
I/O 시간을 나타내는 식
TI/O = Tseek + Trotation + Ttransfer
I/O 속도(rate, RI/O)를 나타내는 식
RI/O = SizeTransfer / TI/O
37.5 디스크 스케줄링
운영체제가 디스크에게 I/O 요청을 하면 디스크 스케줄러는 다음에 어떤 I/O를 처리할 지 결정한다.
디스크 스케줄링은 요청 작업이 얼마나 길지 예측이 가능하기 때문에 SFJ(shotest job first, 짧은 작업 우선) 원칙을 따르려고 한다.
SSTF: 최단 탐색 시간 우선
초기 디스크 스케줄링은 최단 탐색 시간 우선(shortest seek time first, SSTF) (또는 최단 탐색 우선(shortest-seek-first, SSF) 이라고도 불림) 을 사용했다.
SSTF 는 트랙을 기준으로 I/O 요청 큐를 정렬하여 가까운 트랙의 요청을 먼저 처리한다.
문제점
- 드라이브의 구조는 호스트 운영체제에게 공개되어 있지 않고 운영체제는 블럭들의 배열로 인식하는 문제
- 이 문제를 해결하기 위해 운영체제는 SSTF 대신 가장 가까운 블럭 우선(Nearest-block-first, NBF) 방식을 사용
- 기아 현상(starvation)
- 다른 트랙에 있는 요청들이 무시될 수 있음
엘리베이터(SCAN 또는 C-SCAN 이라고 함)
- SCAN 알고리즘
- 트랙의 순서에 따라 디스크를 앞뒤로 가로지르며(스위프(sweep)) 요청을 서비스
- 가까운 층이 아닌 위, 아래로 이동하는 엘리페이터와 같다하여 엘리페이터 알고리즘
- F-SCAN 알고리즘
- 스위프하는 동안에 큐를 동결
- 늦게 도착한 요청들의 처리를 지연시켜 요청에 대한 기아 현상을 없앰
- C-SCAN 알고리즘 (Circular SCAN)
- 스위프하는 방향이 양 방향이 아닌, 밖에서 안으로만 스위프
문제점
- SJF 원칙을 지키기 위해 최선을 다하지 않음 (회전 무시)
SPTF: 최단 위치 잡기 우선
디스크 회전 비용을 고려하기 위해 최단 위치 잡기 우선(shortest positioning time first, SPTF) (또는 최단 접근 시간 우선(shortest access time first, SATF)) 을 이용한다.
탐색과 회전에 걸리는 시간이 다르기 때문에 상황에 따라 다음 차례가 달라진다.
SPTF가 유용하고 성능을 개선할 수 있다.
하지만 운영체제가 트랙의 경계 또는 디스크 헤드가 어디있는지 알 수 없기 때문에 드라이브 내부에서 실행된다.
다른 스케줄링 쟁점들
- 디스크는 상세한 트랙 배치 정보와 헤드의 위치 정보로 최선의 순서(SPTF)로 정렬
- I/O 병합(I/O merging)
- 디스크로 내려보내는 요청의 개수를 줄여 오버헤드 감소
- 작업 보전(work-conserving)
- 디스크가 유휴 상태가 되지 않도록 함
- 작업 비보전(non-work-conserving)
- 예측 디스크 스케줄링(anticipatory disk scheduling) 으로 잠시 기다리는 것이 더 좋을 수 있음
38장. Redundant Array of Inexpensive Disks (RAID)
Redundant Array of Inexpensive Disks 또는 RAID 로 알려진 기술에 대해 알아본다.
이 기술은 고속이면서 대용량의 디스크 시스템을 만든다.
RAID 는 하나의 디스크처럼 보이지만 내부에는 여러 개의 디스크와 메모리, 시스템을 관리하기 위한 프로세서들로 이루어져있다.
RAID 하드웨어는 컴퓨터 시스템과 유사하며 디스크의 그룹을 관리하기 위한 시스템이다.
장점
RAID 는 장점들을 투명하게 제공하여 확산력(deployability)을 개선 시켰다.
사용자와 관리자가 소프트웨어 호환성을 걱정하지 않고 사용할 수 있다.
- 성능
- 디스크 여러 개를 병렬적으로 사용하여 I/O 시간 개선
- 용량
- 많은 디스크 공간으로 데이터 양이 많음
- 신뢰성
- 데이터 중복 기술(redundancy) 으로 디스크 한 개의 고장 감내 가능
38.1 인터페이스와 RAID 의 내부
RAID 도 선형적인 블럭들의 배열로 보이며 파일 시스템이 각 블럭을 읽거나 쓸 수 있다.
파일 시스템이 논리적 I/O 요청을 하면 내부에서 요청 가능한 디스크를 계산하고 물리적으로 I/O 를 발생시킨다. (2개의 복사본을 유지한다면 두 번 물리적 I/O 실행)
38.2 결함 모델
RAID 는 특정 종류의 결함을 파악하고 복구하도록 설계되었다.
- 고장시 멈춤(fail-stop) 결함 모델
- “정상 작동” 이거나 “멈춤” 상태로 있다고 가정
- 동작 중인 디스크에 모든 블럭을 읽거나 쓸 수 있음
- 멈춤 상태의 디스크는 완전히 사용 불가능
- 디스크가 고장나면 쉽게 파악할 수 있다고 가정한다는 것이 단점
38.3 RAID 의 평가 방법
- 용량
- 클라이언트가 사용할 수 있는 유효 용량 평가
- 중복 저장이 없다면 N*B
- 두 개의 복사본을 갖는다면 (N*B)/2
- 신뢰성
- 몇 개의 디스크 결함을 감내할 수 있는지 평가
- 성능
- 워크로드에 따라 크게 달라지기 때문에 평가가 어려움
38.4 RAID 레벨 0: 스트라이핑
RAID 레벨 0 또는 스트라이핑(striping) 방식은 성능과 용량에 대한 훌륭한 상한 기준을 나타낸다.
이 방식은 블럭들을 여러 디스크에 걸쳐 줄을 긋는 것 처럼 저장한다. (중복 저장을 하지 않음)
디스크 배열의 블럭들을 라운드 로빈 방식으로 디스크를 가로질러 펼친다.
연속적인 청크에 대해 요청을 받았을 때 병렬성을 가장 잘 활용하도록 설계되었다.
같은 행에 있는 블럭들은 스트라이프(stripe) 라고 한다.
| 디스크0 | 디스크1 | 디스크2 | 디스크3 |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 |
청크 크기
청크 크기는 RAID 성능에 영향을 준다.
- 작은 청크 크기
- 많은 파일들이 여러 디스크에 걸쳐 스트라이프 되어 병렬성이 증가
- 여러 디스크에서 찾아 블럭 위치를 찾아야 하므로 찾는데 오래 걸림
- 큰 청크 크기
- 병렬성이 감소되어 처리 성능을 높이기 위해서는 여러 요청을 병행하게 실행해야 함
- 위치 찾는 시간 감소
RAID-0 분석으로 돌아가서
- 유효 용량
- B 개의 블럭을 갖는 N개의 디스크라면 N*B 만큼의 유효 용량
- 신뢰성
- 어느 디스크라도 고장나면 전체 디스크 손실
- 성능
- 병렬로 사용자 I/O 요청 처리가 가능
RAID-0 의 성능
- 단일 요청의 지연시간
- 한 블럭과 디스크에 대한 요청의 지연 시간은 거의 동일
- RAID 의 정상 상태(steady state) 에서의 처리 성능(throughput)
- 최대 대역폭 기대 가능
- 처리성능은 N(디스크 수) * S(디스크 하나의 순차 접근 대역폭) 와 같음
38.5 RAID 레벨 1: 미러링
첫 번째 RAID 레벨은 RAID 레벨 1 또는 미러링으로 불린다.
각 블럭에 대해 하나 이상의 사본을 둬서 디스크 고장에 대처한다.
| 디스크0 | 디스크1 | 디스크2 | 디스크3 |
|---|---|---|---|
| 0 | 0 | 1 | 1 |
| 2 | 2 | 3 | 3 |
| 4 | 4 | 5 | 5 |
| 6 | 6 | 7 | 7 |
이 방식은 일반적으로 미러링(RAID-1)을 스트라이핑(RAID-0) 하기 때문에 RAID-10 또는 RAID 1+0 이라고 한다.
RAID-1 분석
- 용량
- 비용이 많이 듦
- 미러링 레벨이 2라면 최대 사용 가능한 용량의 반만 사용 가능 (N*B)/2
- 신뢰성
- 디스크 중 고장이 발생해도 감내 가능
- 성능
- 단일 읽기는 단일 디스크에서 읽는 요청의 지연 시간과 동일
- 쓰기의 경우 병렬적으로 이루어지지만, 물리적으로 두 개의 쓰기가 연산되어야 하므로 최악의 탐색과 회전 지연시간에 의해 결정
- 처리 성능
- 순차 쓰기의 경우 N/2 * S 또는 최대 대역폭의 절반의 대역폭
- 순차 읽기 상황도 N/2 * S 으로 동일
38.6 RAID 레벨 4: 패리티를 이용한 공간 절약
패리티 기반의 접근 방법은 저장 공간을 적게 사용하여 미러링 기반 시스템의 공간 낭비를 극복하고자 한다.
하지만 성능 저하가 발생될 수 있다.
| 디스크0 | 디스크1 | 디스크2 | 디스크3 | 디스크4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 4 | 5 | 6 | 7 | P1 |
| 8 | 9 | 10 | 11 | P2 |
| 12 | 13 | 14 | 15 | P3 |
스트라이프마다 중복 정보를 담고 있는 패리티 블럭을 추가한다.
블럭 P1 은 블럭 4,5,6 과 7번으로부터 계산된 중복 정보를 가지고 있다.
고장난 디스크로부터 데이터를 복구하기 위해서는 스 행의 모든 값을 읽은 후 패리티를 통해 올바른 값을 다시 계산 한다.
RAID-4 분석
- 용량
- 디스크 하나를 패리티 정보 저장에 사용하기 때문에 (N-1)*B
- 신뢰성
- 하나만의 디스크 고장 감내 가능
- 두 개 이상의 고장은 복원 불가능
- 성능
- 순차 읽기의 경우 최대 유효한 대역폭은 (N-1)*S MB/s
- 순차 쓰기의 경우 스프라이프 전부 쓰기가 가장 효율적인 방법이므로 (N-1)*S MB/s
특정 블럭과 함께 패리티 블럭을 갱신하는 정확하고 효율적인 두 가지 방법
- 가산적 패리티(additive parity)
- 스트라이프 내의 다른 모든 블록을 병렬로 읽고 새로운 블럭과 함께 갱신
- 디스크의 개수에 따라 계산의 양이 다르기 때문에 많은 수의 읽기 연산이 필요해질 수 있음
- 감산적 패리티(subtractive parity)
- 갱신 하고자 하는 블록과 패리티 값을 읽음 (동일하면 그대로 유지)
- 이전의 패리티 비트를 현재 상태의 반대 값으로 뒤집어서 처리
- Pnew = (Cold ⊕ Cnew) ⊕ Pold
문제점
- small-write 문제
- 쓰기가 동시에 요청되면 패리티 디스크는 병목으로 작용
- 패리티 디스크로 인해 순차적으로 실행되어야 함
38.7 RAID 레벨 5: 순환 패리티
RAID-5 는 RAID-4 와 거의 동일하게 동작하지만 패리티 블럭을 순환(rotate) 하여 small-write 문제를 해결한다.
| 디스크0 | 디스크1 | 디스크2 | 디스크3 | 디스크4 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | P0 |
| 5 | 6 | 7 | P1 | 4 |
| 10 | 11 | P2 | 8 | 9 |
| 15 | P3 | 12 | 13 | 14 |
| P4 | 16 | 17 | 18 | P9 |
RAID-5 분석
많은 부분은 RAID-4와 동일하다.
모든 디스크를 활용할 수 있기 때문에 랜덤 읽기 성능이 약간 더 좋다.
RAID-5 성능이 거의 RAID-4와 동일하기 때문에 RAID-5로 완전히 대체되었다.
38.5 RAID 비교: 정리
성능만을 원하고 신뢰성을 고려하지 않는다면 스트라이핑
임의 I/O 성능과 신뢰성을 원한다면 미러링
순차 I/O 만 사용하거나 용량과 신뢰성이 목적이라면 RAID-5
38.9 RAID 와 관련된 다른 흥미로운 주제들
- 디스크가 고장났을 때 대체용 스페어(hot spare) 로 고장난 디스크를 대신하는 방법도 있음
- 잠재된 섹터 오류(latent sector error) 또는 블럭 훼손(block corruption) 을 고려한 모델들도 있음
- 소프트웨어 레이어로 RAID(소프트웨어 RAID) 구성도 가능.
- 저렴하지만 일관성-유지 등의 문제 발생
39장. 막간: 파일과 디렉터리
이번 장에서는 하드 디스크 드라이브 또는 솔리드 스테이트 드라이브(Solid-state storage, SSD) 와 같은 영속 저장 장치(persistent storage) 개념을 다룬다.
영속 보존 장치는 전원 공급이 차단되어도 데이터를 그대로 보존한다.
39.1 파일과 디렉터리
파일
- 읽거나 쓸 수 있는 순차적인 바이트의 배열
- 각 파일은 저수준 이름(low-level name) 을 가지고 있음
- 저수준 이름을 아이노드 번호(inode number) 라고 함
- 각 파일은 아이노드 번호와 연결되어 있음
- 운영 체제는 파일의 구조를 모르고 파일 시스템이 데이터를 디스크에 저장하고 돌려주는 역할을 함
- 파일의 종류를 나타내는 확장자는 관용적(convention) 일뿐 반드시 지킬 필요는 없음
디렉터리
- 파일와 마찬가지로 저수준의 이름(아이노 번호드)를 가짐
- <사용자가 읽을 수 있는 이름, 저수준의 이름> 쌍으로 이루어진 목록을 가짐
- 각 항목은 파일 또는 다른 디렉터리를 가리킴
- 디렉터리내에 디렉터리를 포함하여, 디렉터리 트리(directory tree, 또는 디렉터리 계층(directory hierarchy)) 구성
- 디렉터리 계층은 루트 디렉터리(root directory) 부터 시작
- 구분자(separator) 를 사용하여 하위 디렉터리 명시
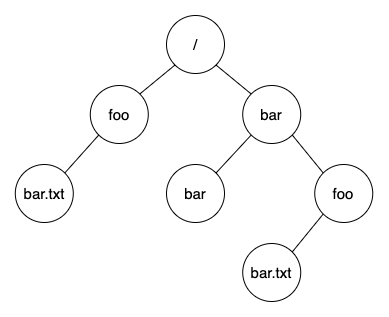
39.2 파일 시스템 인터페이스
파일의 생성, 접근, 삭제 등의 인터페이스를 다뤄본다.
39.3 파일의 생성
int fd = open("foo", O_CREATE | O_WRONLY | O_TRUNC, S_IRUSR | S_IWUSR);
open 시스템 콜로 파일 생성할 수 있다.
O_CREATE: 파일이 없으면 생성O_WRONLY: 쓰기 전용O_TRUNC: 파일의 크기를 0byte 줄여서 내용 삭제S_IRUSR | S_IWUSR: 소유자만 읽기, 쓰기 권한 설정- 파일 디스크립터(file descriptor)
open()의 반환 값- 프로세스마다 존재하는 정수로 파일을 접근하는 데 사용 (권한 필요)
read(),write()등의 메소드로 파일 접근 가능
39.4 파일의 읽기와 쓰기
프로그램이 호출하는 시스템 콜을 추적하는 Linux 의 strace 를 통해 cat 동작을 살펴본다.
- 파일을 읽기 전용으로 열기 (표준 입력(0), 출력(1), 에러 파일(2) 디스크립터가 열기기 때문에 반환값이 3)
read()시스템 콜로 파일에서 반복적으로 읽음write()시스템 콜에서 표준 출력(STDOUT) 하기 위해 파일 디스크립터 1 사용 (화면 출력)- 파일 내용을 더 읽으려고 시도 (남은 바이트가 없어서 0 반환)
close()로 파일 할 일 끝남
prompt> strace cat foo
...
open("foo", O_RDONLY | O_LARGEFILE) = 3
read(3, "hello\n", 4096) = 6
write(1, "hello\n", 6) = 6
hello
read(3, "", 4096) = 0
close(3) = 0
...
39.5 비 순차적 읽기와 쓰기
파일의 임의의 오프셋부터 읽거나 써야 할 때가 있다.
off_t lseek(int fildes, off_t offset, int whence);
fildes: 파일 디스크립터offset: 오프셋whence: 탐색 방식 결정SEEK_SET: 오프셋은 offset 바이트로 설정SEEK_CUR: 현재 위치에 offset 바이트를 더한 값으로 설정SEEK_END: 파일의 크기에 offset 바이트를 더한 값으로 설정
39.6 공유하는 파일 테이블의 요소들: fork() 와 dup()
각 프로세스는 개별적인 열린 파일 테이블의 요소를 다룬다.
같은 파일에 대한 논리적 읽기와 쓰기는 독립적이며 개별적인 현재 오프셋을 관리한다.
fork()- 부모 프로세스가
fork()으로 자식 프로세스를 생성하면 파일 테이블은 공유 - 파일 테이블의 요소가 공유되면 참조 횟수(reference count) 가 증가
- 부모 자식 프로세스가 모두 종료되어야 요소들 제거
- 부모 프로세스가
dup()- 이미 열려있는 파일의 디스크립터를 참조하는 새로운 파일 디스크립터 생성
- 유닉스 쉘과 출력 재지향하는 경우에 유용
39.7 fsync() 를 이용한 즉시 기록
write()- 영속 저장 장치에 기록 해달라고 파일 시스템에 요청
- 파일 시스템에서 성능을 위해 메모리에 모은 후 (버퍼링) 처리
- 데이터가 유실되는 경우가 발생
fsync()- 파일 시스템이 지정된 파일의 더티(갱신된) 데이터를 디스크에 강제로 기록
- 쓰기들이 처리되면 리턴
39.8 파일 이름 생성
rename(char *old, char *new);
시스템 크래시에 대해 원자적 으로 구현되어 있음 (중간 상태가 없음)
39.9 파일 정보 추출
파일에 대한 정보를 메타데이터(metadata) 라고 한다.
메타데이터를 보려면 stat() 이나 fstat() 를 사용한다.
struct stat {
dev_t st_dev; // 파일이 있는 장치의 ID
ino_t st_ino; // 아이노드 번호
mode_t st_mode; // 보호
nlink_t st_nlink; // 하드링크 수
uid_t st_uid; // 소유자의 사용자 ID
gid_t st_gid; // 소유자의 그룹 ID
dev_t st_rdev; // 장치 ID (특수 파일인 경우)
off_t st_size; // 파일 크기 (바이트)
blksize_t st_blksize; // 파일 시스템 입출력의 블록 크기
blkcnt_t st_blocks; // 할당된 블록 수
time_t st_atime; // 최종 접근 시간
time_t st_mtime; // 최종 갱신 시간
time_t st_ctime; // 최종 상태 변경 시간
}
39.10 파일 삭제
prompt> strace rm foo
...
unlink("foo") = 0
...
unlink() 시스템 콜에서는 파일 이름을 인자로 받아서 성공하면 0 리턴
39.11 디렉터리 생성
prompt> strace mkdir foo
...
mkdir("foo", 0777) = 0
...
mkdir() 시스템 콜로 디렉터리 생성한다.
디렉터리에는 자신을 나타내는 “.”(dot) 디렉터리, 부모 디렉터리를 가리키는 “..”(dot-dot) 디렉터리가 있다.
39.12 디렉터리 읽기
디렉터리를 읽는 것은 ls 프로그램이다.
이 프로그램은 opendir(), readdir(), closedir() 시스템콜을 사용한다.
반복문으로 디렉터리 항목을 읽고 이름과 아이노드 번호를 출력한다.
ls 에 -l 플래그를 추가하면 파일 크기 같은 추가 정보를 얻기 위해 stat() 을 호출한다.
39.13 디렉터리 삭제하기
rmdir() 시스템 콜로 디렉터리를 삭제한다.
비어있지 않은 디렉터리에 대해 호출하면 실패한다.
39.14 하드 링크
link() 시스템 콜은 원래의 경로명과 새로운 경로명을 인자로 받는다.
원래 파일 이름에 새로운 이름을 link 하면 동일한 파일을 접근할 수 있는 새로운 방법을 만든다.
prompt> echo hello > file
prompt> cat file
hello
prompt> ln file file2
prompt> cat file2
hello
위와 같이 하드 링크를 생성하면 file 또는 file2 으로 읽을 수 있다.
link() 는 새롭게 링크하려는 이름 항목을 디렉터리에 생성하고, 원래 파일과 같은 아이노드 번호를 가리킨다. (복사되지 않음)
여기서 unlink() 로 한 파일을 삭제해도 다른 이름으로 파일 접근이 가능하다.
unlink() 는 아이노드 번호의 참조 횟수(reference count) 를 검사하고 참조 횟수를 줄이는데,
참조 횟수가 0 되면 파일 시스템은 데이터 블럭을 해제하여 파일을 진정으로 삭제한다.
39.15 심볼릭 링크
하드 링크는 디렉터리에 대해 사용 불가, 다른 디스크 파티션에 있는 파일 링크 불가 등의 제한이 있다.
심볼릭 링크(symbolic link) 또는 소프트 링크(soft link) 는 이런 경우 유용하게 사용할 수 있는 링크다.
심볼릭 링크를 생성하기 위해서는 ln 프로그램에 -s 플래그를 추가하면 된다.
prompt> echo hello > file
prompt> ln -s file file2
prompt> cat file2
hello
prompt> ls -al
drwxr-x--- 2 remzi remzi 29 May 3 19:10 ./
drwxr-x--- 27 remzi remzi 4096 May 3 19:10 ../
-rw-r----- 1 remzi remzi 6 May 3 19:10 file
lrwxr-x--- 1 remzi remzi 4 May 3 19:10 file2 -> file
file과 file2 모두 접근이 가능하다.
하드 링크와 유사해보이지만 다음과 같은 차이가 있다.
- 심볼릭 링크는 다른 형식의 독립된 파일 (파일, 디렉터리와 다름)
- 소프트 링크 가장 왼쪽에
l이 표시 - 링크한 대상의 파일이 보임
- 소프트 링크 가장 왼쪽에
- 심볼릭 링크의 크기는 파일의 경로명 길이
- 원래 파일을 삭제하면 심볼릭 링크가 가리키는 실제 파일도 삭제됨
39.16 권한 비트와 접근 제어 목록
파일 시스템은 디스크에 대한 가상화를 제공하여 디스크상의 블럭들을 파일과 디렉터리로 변환한다.
하지만 파일은 다수의 사용나자 프로세스들이 공유하므로 파일 시스템은 공유범위를 한정하는 기법들도 제공한다.
권한 비트(permisision bits)
prompt> ls -l foo.txt
-rw-r--r-- 1 remzi remzi 0 May 3 19:10 foo.txt
-rw-r--r-- 은 에서 첫 번째 글자는 파일의 종류를 의미한다.
- 일반 파일, d 디렉터리, l 심볼릭 링크를 나타낸다.
그 이후의 아홉 개 글자는 소유자(owner), 그룹(group), 나머지 사용자(other) 으로 세 개의 그룹으로 나누어진 권한을 의미한다.
이 그룹들이 할 수 있는 일은 읽기(r), 쓰기(w), 실행하기(x) 다.
파일 모드(file moe) 를 변경하는 chomod 명령으로 권한의 설정을 변경할 수 있다.
접근 제어 목록(access control list)
AFS와 같은 분산 파일 시스템을 포함하는 다른 파일 시스템의 경우 디렉터리마다 접근 제어 목록(access control list, ACL) 을 가지고 있다.
접근 제어 목록은 누가 특정 자원을 접근할 수 있는지 명확하게 표현한다.
39.17 파일 시스템 생성과 마운트
다수의 파일 시스템 파티션들이 존재할 때는 마운트를 통해 단일 디렉터리 트리 구성이 가능하다.
많은 파일 시스템에서 mkfs 로 파일 시스템을 생성할 수 있다.
이 새로운 파일 시스템을 루트 디렉터리에서 시작하는 기존의 디렉터리 구성으로 접근할 수 있도록 하는 작업을 마운트라고 한다.
mount 프로그램으로 기존의 디렉터리 중 하나를 마운트 지점(mount point) 으로 지정하여 새로운 파일 시스템을 붙여 넣는다.
40장. 파일 시스템 구현
이번 장에서 vsfs(Very Simple File System) 라는 간단한 파일 시스템에 대해 알아본다.
40.1 생각하는 방법
파일 시스템의 두 가지 측면에 대해 알아본다.
- 자료 구조
- 간단한 파일 시스템은 블럭과 다른 객체들을 배열과 같은 간단한 자료 구조
- 다른 파일 시스템은 복잡한 트리 기반의 자료 구조
- 접근 방법(access method)
- 프로세스가 호출하는
open(),read(),write()등의 시스템콜을 실핼할 때 어떻게 동작하는지
- 프로세스가 호출하는
40.2 전체 구성

vsfs 파일 시스템의 자료 구조에 대해 디스크를 블럭(block) 들로 나누어 알아본다. 4KB 블럭이 64개 나열된 작은 디스크를 가정한다.
- 데이터 영역(data region)
- 사용자 데이터가 있는 디스크 공간
- 데이터 블럭(D)
- 아이노드(inode)
- 파일에 대한 메타데이터(metadata)
- 파일 크기, 소유자, 접근 권한, 접근과 변경 시간 등과 같은 정
- 아이노드 블럭(I)
- 아이노드 테이블(inode table)
- 아이노드들의 저장을 위한 디스크 공간
- 아이노드들이 배열형태로 저장
- 슈퍼블럭(superblock)
- 파일 시스템 전체에 대한 정보 (아이노드와 데이터 블럭 개수, 아이노드 테이블 시작 위치 등)
각 블럭이 현재 사용 중인지 아닌지는 할당 구조(allocation structure) 로 표현해야 한다. 사용 여부를 표현하는 데에는 다양한 방법이 존재한다.
- 프리 리스트(free list)
- 사용 중이 아닌 블럭들을 링크드 리스트 형태로 관리
- 비트맵(bitmap)
- 데이터 비트맵(data bitmap): 데이터 영역에 있는 블럭들의 사용여부 표시 (d)
- 아이노드 비트맵(inode bitmap): 아이노드 테이블에 있는 아이노드들의 사용여부 표시 (i)
40.3 파일 구성: 아이노드
아이노드(inode) 는 인덱스 노드(index node) 의 줄임말로 디스크 자료 구조 중 가장 중요하다.
각 아이노드는 아이-넘버(i-number) 라는 숫자로 표현되는데 이를 저수준 이름(low-level name) 이라고 한다.
아이노드에는 파일의 종류, 크기, 할당된 블럭 수, 보호 정보, 시간 정보, 데이터 블록의 디스크 위치 등과 같은 메타데이터(metadata) 가 저장되어 있다.
데이터 블럭의 위치를 표현하는 가장 간단한 방법은 직접 포인터(direct pointer) 를 두는 것이지만 파일 크기의 제한이 있다.
멀티 레벨 인덱스
큰 파일을 지원하기 위한 일반적인 방법은 아이노드 내에 간접 포인터(indirect pointer) 를 두는 것이다.
간접 포인터는 데이터 블럭의 위치를 가리키지 않고 데이터 블럭을 가리키는 포인터들이 저장된다.
더 큰 파일을 저장하고 싶으면 이중 간접 포인터(double indirect pointer), 삼중 간접 포인터(triple indirect pointer) 등을 둘 수 있다.
이러한 구성 방식을 멀티 레벨 인덱스 기법이라고 한다.
40.4 디렉터리 구조
디렉터리의 데이터 블럭에는 문자열과 숫자가 쌍으로 존재하며 문자열 길이에 대한 정보도 있다.
대부분의 파일 시스템에서는 디렉터리들을 특수한 종류의 파일로 간주한다.
디렉터리는 자신의 아이노드를 가지며, 아이노드의 type 필드에 디렉터리 라고 명시되어 잇다.
40.5 빈공간의 관리
파일 시스템은 아이노드와 데이터 블럭 사용 여부를 관리하는 빈 공간 관리(free space management) 로 파일이나 디렉터리를 할당할 공간을 찾는다.
파일 시스템은 선할당(pre-allocation) 정책으로 연속된 블럭들이 비어있는 공간 할당하여 파일에 대한 입출력 성능을 개선한다.
40.6 실행 흐름: 읽기와 쓰기
파일 시스템 동작을 이해하기 위해 실행 과정(access path) 에 대해 알아본다.
디스크에서 파일 읽기
open("foo/bar", O_RDONLY)호출- 항상 루트 디렉터리(root directory) 에서 시작하여 루트 디렉터리의 아이노드 읽음
- 아이노드에서 데이터 블럭의 포인터 추출 하여 디렉터리 정보 읽기
- 디렉터리 정보를 통해
foo항목 찾기 foo의 아이노드 블럭과 데이터를 읽은 후bar아이노드 번호 찾기open()에서bar에 대한 아이노드를 메모리로 읽어 들임- 파일에 대한 접근 권한을 확인하고 파일 디스크립터를 할당받아 사용자에게 리턴
read()를 통해 파일 읽기
디스크에 파일 쓰기
- 파일을 열기
write()를 호출하여 새로운 내용으로 파일 갱신
40.7 캐싱과 버퍼링
대부분의 파일 시스템들은 자주 사용되는 블럭들을 메모리(DRAM)에 캐싱한다.
캐싱을 하지 않으면 아이노드와 디렉터리 데이터 읽기로 최소 두번의 읽기가 필요하다.
초기 시스템은 고정 크기의 캐시(전체 메모리의 약 10%)를 가지고 캐시 교체 정책들로 어떤 블럭들을 남길지 결정했다.
현대 시스템은 동적 파티션 방식을 사용한다.
가상 메모리 페이지와 파일 시스템 페이지들을 통합하여 일원화된 페이지 캐시(unified page cache) 를 사용한다.
이를 통해 파일 시스템과 가상 메모리에 융통성있게 메모리를 할당할 수 있다.
캐시를 이용하면 쓰기의 경우 쓰기 버퍼링(write buffering) 이 가능하여 일괄처리(batch) 가 가능하다.
- 첫번째 갱신에 대한 쓰기를 연기하여 두 번째 연산과 병합 가능 (I/O 줄임)
- 쓰기 요청들을 모아 I/O 들을 스케줄하여 성능 개선
- 쓰기 자체 회피 가능 (생성 후 즉시 삭제한다면 생성할 필요가 없음)
데이터가 유실되지 않도록 강제적으로 기록하려면 fsync() 를 사용한다.