IT 환경에서는 시간을 단축시키는 것이 중요하다.
오브젝트 책을 참고하여 추상화를 공부하고 객체 지향 개발을 통해 변경사항을 격리시키자.
Philosophy(철학)
1. Relativism(상대 주의) : 토마스 쿤(과학혁명의 구조)
- 과학은 상대적이다 주장 (절대적인 진리 부정)
- 사람들이 천동설을 믿고 있으면 천동설이고 지동설을 믿고 있으면 지동설이 된다
- ex) 최소 단위가 분자 -> 원자로 변환
2. Rationalism(합리 주의) : 러커토시 임레(수학적 반겨의 논리: 증명과 반박)
- 토마스 쿤의 내용을 반박
- 과학은 합리적이다 주장
- 과학은 바른 방법이 있고 합리성이 존재
- 과학은 여론조성해서 만들어 낼 수 없는 것이다.
난장판 : 파울 파이어아벤트
코드의 틀
켄트벡은 생각하는 코드의 틀 가치, 원칙, 패턴 3가지가 있다고 말했다.
패턴 은 가치와 원칙을 기반으로 반복되는 유형이기 때문에 상위 단계에 가치와 원칙이 존재한다고 한다.
강의에서는 Object 책의 패러다임에 가까운 Xoriented 도 추가하여 설명해주었다.

1. Value(가치)
다음 3가지 가치를 추구해야 하며 코드를 작성한다.
-
Communication(커뮤니케이션)
- 무엇가 개발을 할 때는 커뮤니케이션이 잘되는 방향으로 짜라.
- 유지보수가 쉬워야 한다. -
Simplicity(간단)
- 되도록이면 간단하게 짜라
- 간단하게 짤수록 좋다. -
Flexibility(유연성)
- 유연하게 짜라
- 유연하다는건 간단하게 생긴 것들만 가능하다.(유연성을 얻으려면 간다하게 짜라)
- 실제로 작성한 메소드보다 Math.sign 처럼 값 하나만 출력하는게 많이 사용된다.
- 유연하게 코드를 작성하면 간단해지고 커뮤니케이션도 좋아질 것이다.
2. Principle(원칙)
- 원칙은 가치와는 무관하게 모두 같이 지킴으로써 가치가 발생하는 행위이다.
- 안지켜진 부분이 있으면 버그로 보게 될 수도 있기 때문에 다같이 지켜야한다.
- 예외적인 상황을 즉각적으로 인식할 수 있어야 한다.
-
원칙은 여러 레이어에 걸쳐서 이루어진다.
- Local consequences
- 변수의 생명주기는 짧게 가져갈 것
- 길게 가져가면 변수를 어디서 어떻게 생성했는지 모른다.
- Minimize repetition
- 중복 최소화
- 중복은 제거하는게 아니라 발견하는 것이다.
- 실력이 좋아지면 반복이라고 느껴지지 않았던 점들이 반복으로 보일 수 있다.
- Symmetry
- 되도록이면 짝을 맞춘다. (ex. getter 있으면 setter 도 만들기)
- 사람 기본 논리는 흑백 논리에서 시작 된다.
- 사람은 이진을 반복해서 생각하는게 빠르다. (이진 트리가 구축이 안되면 당황하게 된다.)
- Conversion
- convention 을 지키면서 만든다
- Local consequences
3. Xoriented
- OOP : SOLID, DRY… (Object 책에서 다룰 부분)
- Reactive
- Functional
Conclusion
IT 환경에서는 100% 인건비 (시간 = 비용) 이기 때문에 시간을 단축 시키는게 중요하지만, 실제로 75% 정도를 디버깅이나 추가, 변경 요구 사항이 있으면 수정하는데 사용된다. 물론, 코드가 유연, 견고, 격리 되지 않아서 시간이 소비되는 것이다. 추가, 변경 요구 사항을 받아들일 수 있도록 격리가 필요하다. 변화율에 따른 격리에 성공하는 방법으로 역할 모델이 있는데 이 책에서 그러한 방법을 알려주고 있다. 책을 읽고 역할 모델별로 엔티티를 나누고 객체들을 설계하여 객체지향 세계에 입문하는 것을 목표로 한다.
이후에 value, principle, Xoriented 3가지를 고려하여 자주 사용되는 패턴을 정리하고 즉각 적용할 수 있는 best practice 를 만들면 시간을 크게 단축하자.
추상화
역할 모델을 이해하려면 추상화에 대해 이해가 필요하다.

Generalization : 일반화 - modeling, function, algorithm
- 수학에서 온 개념
- 다양한 현상을 하나로 설명할 수 있는 방법
- 공통점이나 설명할 수 있는 공식을 만들어서 나머지 현상에 적용할 수 있게 만드는 것
Association : 연관화 - reference, dependence
- 한번에 복잡한 것을 사용하지 않고 다른 객체에게 위임하여 신경쓰지 않는다.
- 넓게 보지 않고 하나의 작은 객체만을 생각하면 단순해질 수 있다.
Aggregation : 일반화 - group, category
- 여러가지 집합체를 통틀어 가르키는 것
1. Data Abstract
데이터는 동작, 행위가 존재하지 않는다.
데이터의 추상화 방법론 3가지
modeling
- 특정 목표에 따라서 기억해야만 할 것을 추려내는 것
- 목적에 맞게 필요한 것들만 추려내는 것
Categorization
- 카테고리로 잘 만들어서 카테고리로 인식하는 것
Grouping
- 모아두는 것
- 추상화를 할 때, 강력한 체계
2. Procedural Abstract (이 책에서 전반적으로 다룰 내용)
Procedure 는 절차적이라는 의미가 아니라 고유 명사
쉽게 말해 메소드가 아니라 데이터를 맡기고 처리를 위임하는 함수를 의미한다.
Generalization
- 일반화된 방법을 사용할 수록 함수를 여러개 만들 필요가 없다.
- 문제점 : 머리가 좋아야 가능하다.(우리들은 머리가 나쁘다)
- 가장 많이 사용되는 방법
Capsulization
- 보다 추상적인 행위를 표현하는 것(은닉화와 다름)
- 사용자의 질이 높아져야 한다.
- 모듈을 모든 사용자에게 제공하려면 무조건 캡슐화가 필요
3. OOP Abstract (객체 지향적인 추상화)
객체 지향에서 사용되는 방법
UML 에서 class diagram 을 그릴 때 사용하실 수 있는 class 간의 연결 관계를 표현하는 방법
객체 지향에서는 1.Data 와 2.Procedure 방법론을 모아서 사용하기 때문에 모든 추상화 기법을 사용한다.(추상화 지옥)
Object 책에서는 현존하는 모든 추상화 기법을 요구하고 있다.
Generalization
인터페이스나 추상 클래스를 표현
Realization
일반화한 것으로부터 파생되어있는 구상 클래스를 만드는 것
Dependency
함수의 인자를 받거나 부분적으로 참조할 때 임시적으로 메소드가 인자받을 때만 사용해야 되는 것
Association
영혼의 단짝 필드같은 곳에 정의되어 있는 dependency
Directed Association
Aggregation Composition
Timing
이 책에서는 기본적으로 Timing 을 언급하고 있다
프로그램 : 메모리에 적재되서 실행될 때 프로그램이라 말한다.
개발자가 발생 시킬 수 있는 에러 3가지 Lint Time Error, Compile Time Error, Run Time Error
이 외에도 Run time 이후에도 발생되지 않는 에러 Context Error 가 존재하지만 발견할 방법이 없다.
Run Time error 는 대부분 잡을 수도 없고 재현하기도 힘들다.
그래서 Lint Time 이나 Compile Time 에서 에러를 받는것이 가장 좋다.
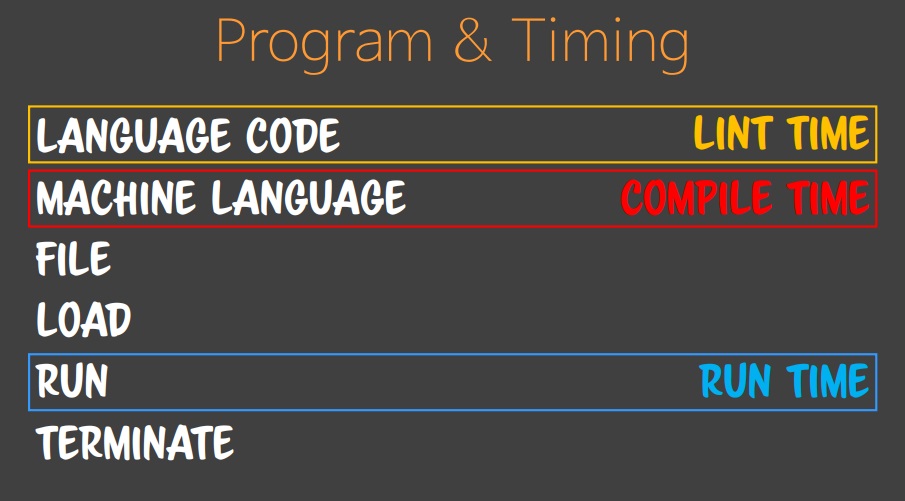
- Language Code : Lint Time
코드 품질을 위해서 코드를 계속 감시하는 Lint 단계 - Machine Language : Compile Time
컴파일러가 사람이 잡을수 없는 여러가지 요인을 잡아주는 단계 - File
- Load
- Run : Runtime
- Terminate
Run

위의 코드에서 모두 Runtime 인 상태에도 불구하고 함수나 클래스를 선언 하는 Time 이 있고 사용하는 Time 으로 나눌 수 있다. 사용되는 Time 에서는 상대적으로 선언되는 부분이 정적 타입으로 보일 수 있다. Run Time 이라는 것은 상대적인 것이다.
Point of Point

B가 A의 주소를 가리키고, C와 D가 B랑 똑같은 값을 갖도록 만들었다면, B안에는 값이아니라 주소이기 때문에 C와 D도 값이 아니라 주소 값이 복사가 되고 위 그림과 같이 A를 가리키게 될 것이다.
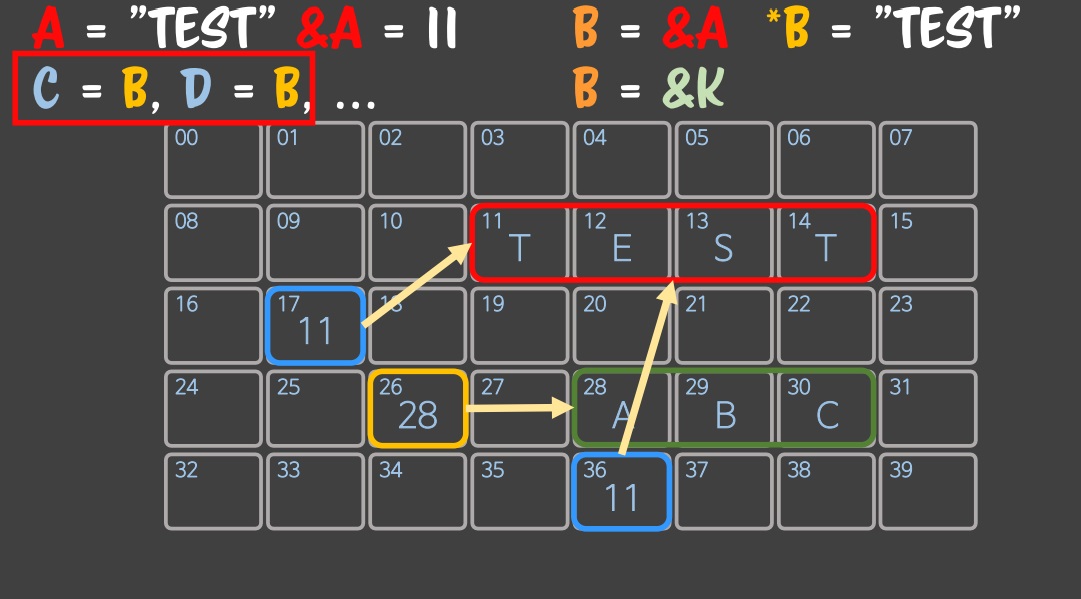
하지만 위와 같이 B가 K를 가리키게 된다고 한다면 모순이 생긴다.
C와 D는 B와 같다고 선언했지만 B의 변화를 따라가지 못한다.
C와 D는 여전히 B와 같다고 생각하고 있지만 이미 B는 다른 값을 가지게 되서 오류가 생기게 된다.
이런 것을 참조 전파라고 한다. 참조는 한번 만들어서 노출 되면 무조건 전파되서 이런 현상이 일어난다.
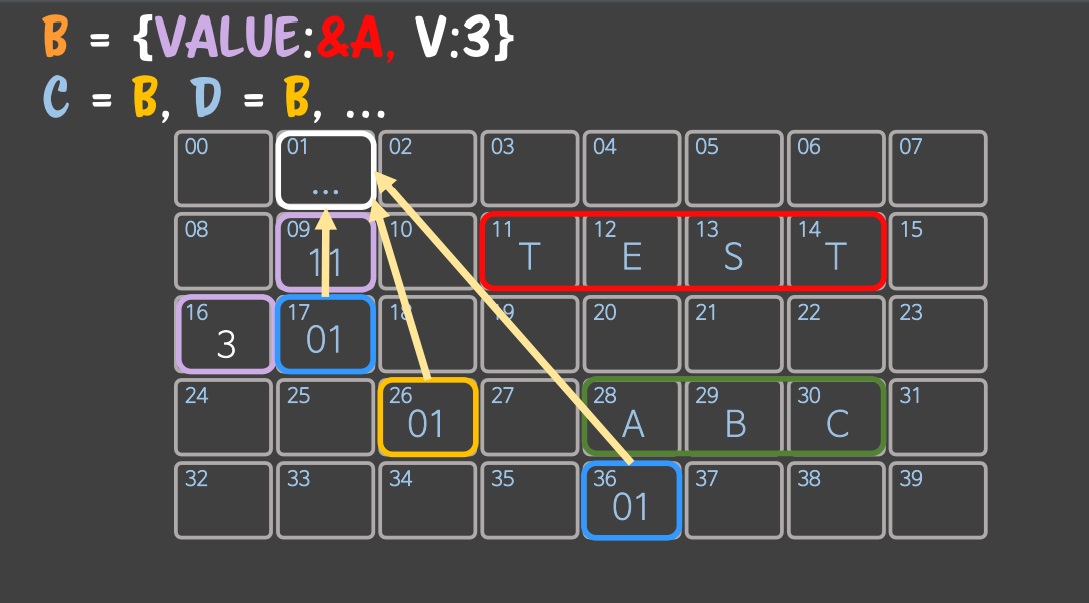
참조 전파로 인한 문제를 해결하기 위해서 value 와 v 키를 가진 객체를 가르키는 하얀색 메모리를 생성하고 B에 그 주소를 할당한다.
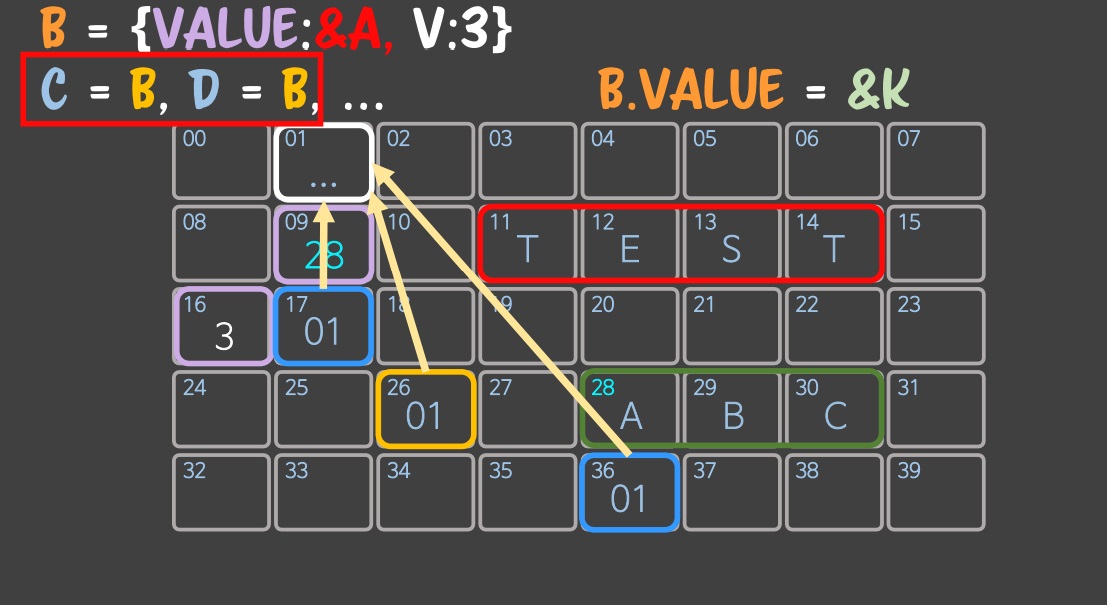
B.value 를 변경한다고 하면 위와 같이 나오게 될것이다.
B.value 가 변경되더라도 C와 D는 똑같이 하얀 메모리 주소를 참조하고 있기 때문에 B,C,D는 모두 같은 값을 가리키고 있다.
이게 바로 객체지향의 인터페이스를 정의하면 그 함수가 구상 클래스를 호출할 수 있는 원리,
링크드 리스트 원리, 데코레이션 패턴의 원리 등등 의 원리이다.
참조를 직접 잡지 않고 참조를 잡고 쿠션을 잡고 다시 참조를 통해 접근 하는 것, 이 책에서는 동적 바인딩이라고 표현하지만 이것이 Point of Point 이다. 우리는 직접 참조를 되도록이면 지양하고 참조의 참조 기법을 사용하는 것이 run time 기법에 안전하다. 그래서 객체 지향에서는 값을 사용하지 않고 참조를 사용한다.