절차대로 프로그램을 쪼개거나 데이터를 기준으로 추상화를 하면 로직이 쉽게 오염될 수 있다.
데이터가 없는 상태에서 객체 지향 추상화를 하고 type으로 구분한다.
분해
프로그래밍적으로 독립된 부품들을 조립해서 만들어진 결과물을 composition 상태로 만들어졌다고 한다.
composition 상태에서의 부품들은 변하지 않는 속성이 있어서 각자의 가치가 있다.
하지만, assemble 상태에서의 부품들은 속성이 없기 때문에 조립한 결과에서만 가치가 생긴다.
소프트웨어가 격리, 모듈화가 잘되있다면 composition 이라고 하지만, 얽혀있는 상태라면 assemble 로 되어 있다고 한다.
도메인을 파악하는 과정은 시간순으로 이뤄지기 때문에 잘 격리되지 않고 assemble 상태로 만들어지게 된다.
decomposition 을 통해서 composition 상태로 만들어 복잡성 폭발을 해결해야 한다. 그래서 이번에는 복잡한 현실 세계를 어떻게 decomposition 할 것인가를 설명한다.
책에서는 3가지 분해 방법이 나온다.
1. Functional decomposition (기능적으로 분해)
여기서의 Functional 은 수학적인 용어이기 때문에 기능적인이라는 뜻만이 아니라 함수를 이라고 해석해도 무방
Flow chart 기법
하나의 flow 로 이루어졌다고 생각해서 프로그램을 쪼갤 수 있다고 생각하기 때문에 Function decomposition 이 일어난다.
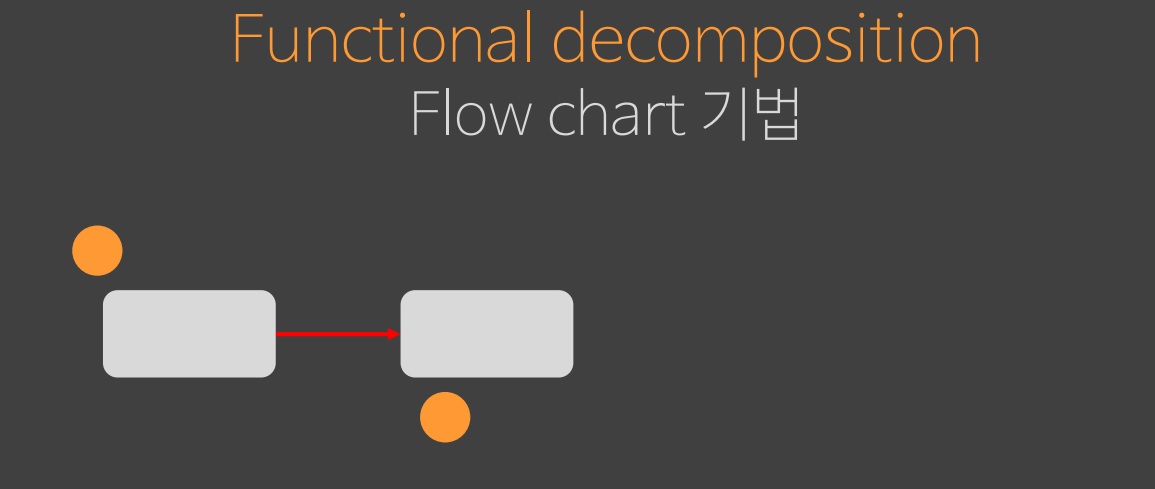
주황색 상태를 처리하기 위한 flow 가 있고 다음 단계까지도 주황색 상태를 가공하려고 한다. 여기서 말하는 상태들은 flow 바깥쪽에 존재하는 전역 변수이다.
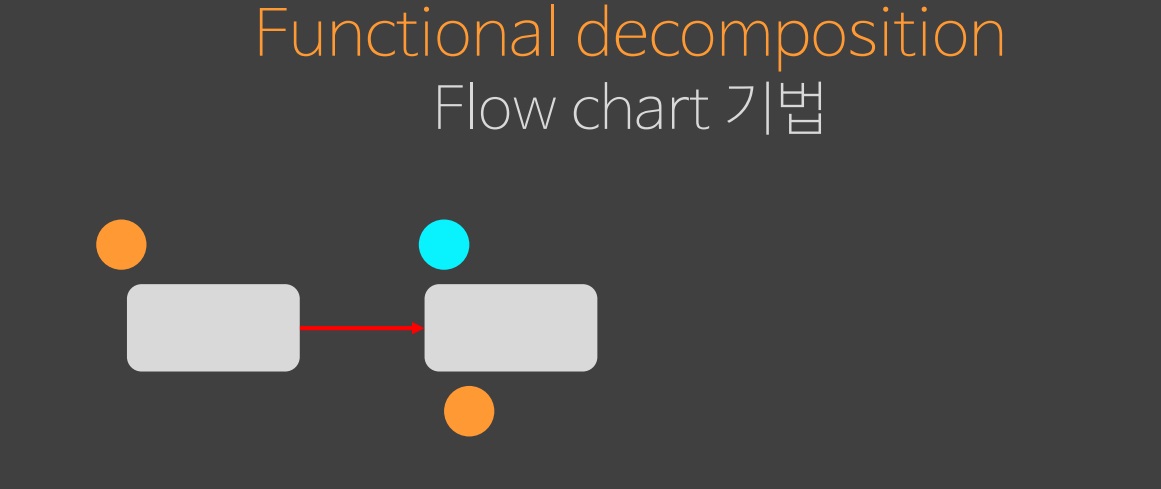
하지만 두번째 단계에서 하늘색 상태가 필요한 것을 알게 됐고 처음부터 하늘색 상태가 필요하다고 생각한다.
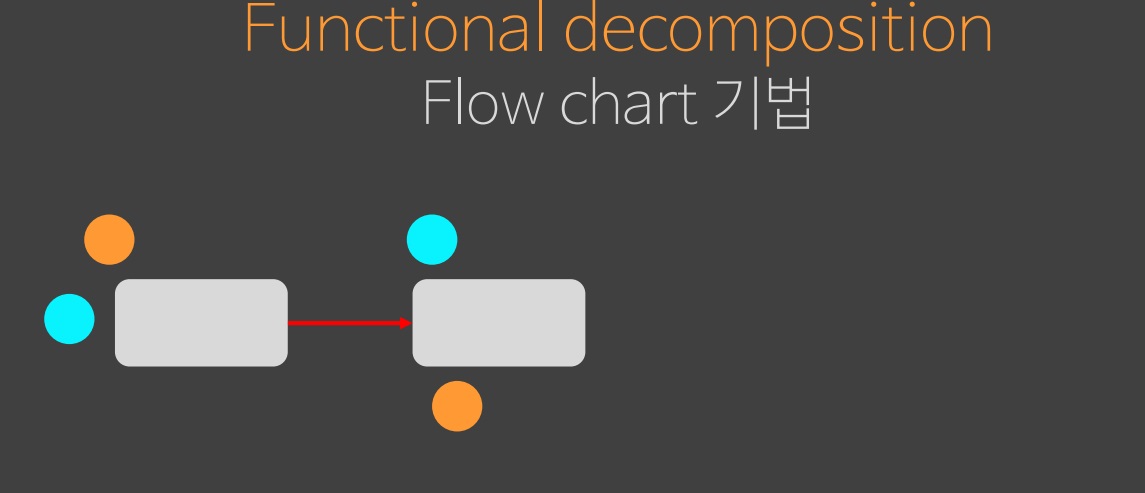
이 하늘색 상태는 2단계에서 사용하려고 할 때 생성 되는게 아니라 처음부터 존재했어야 되므로 1단계에도 추가된다. 그럼, 이 flow 는 기반된 상태가 달라졌기 때문에 오염돼서 처음부터 다시 만들어야 한다.
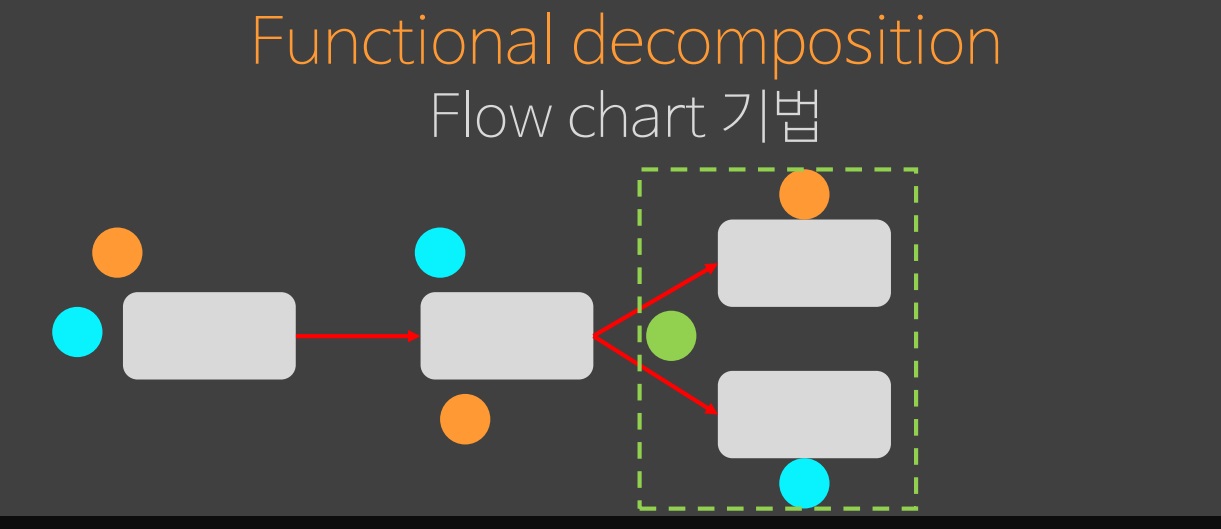
더 나아가, flow 를 처리하면서 분기를 해야 되는 것을 알았고 특정 조건 초록색 상태에 따라 처리를 하도록 한다. 이 초록색 데이터는 분기에만 사용되고 다른 곳에서는 사용되지 않기 때문에 scope 를 이용해서 변수의 유효범위를 정할 수 있다. scope 는 flow 시스템상에서로직을 전체를 검토하지 않도록 해주기 때문에 초록색 상태는 scope 를 벗어날 때 존재하지 않기 때문에 앞의 단계를 고칠 필요가 없다. 이러한 장점으로 scope 를 짧게 선언하고 되도록이면 빨리 라이프사이클을 끝나게 만들어야 한다.
이어서, 최종 단계 작업을 한다.
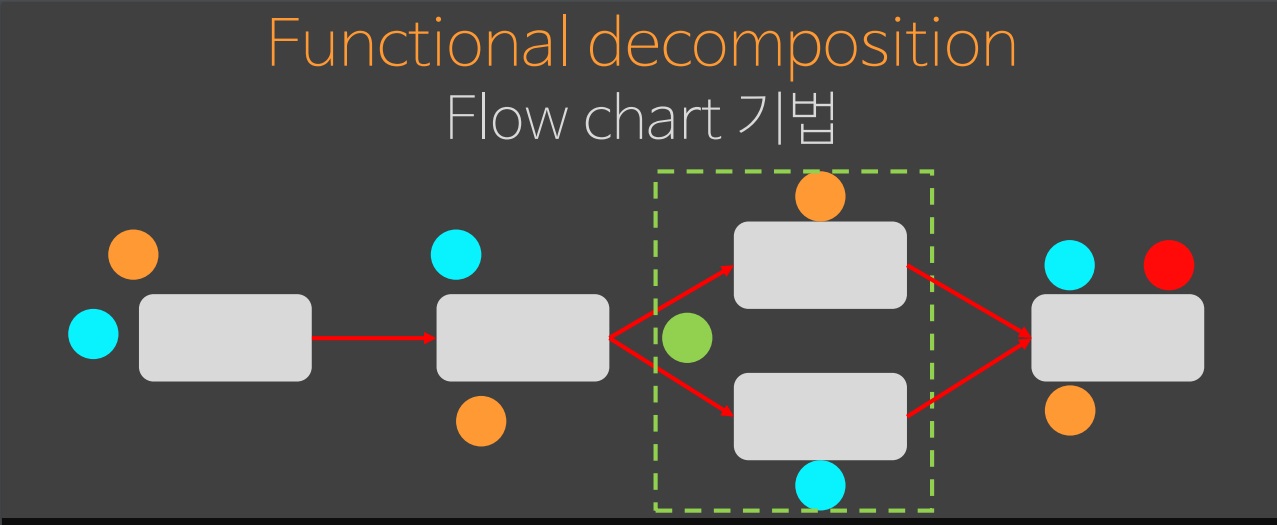
근데 빨간생 상태가 필요하다는 것을 여기서 깨달았고
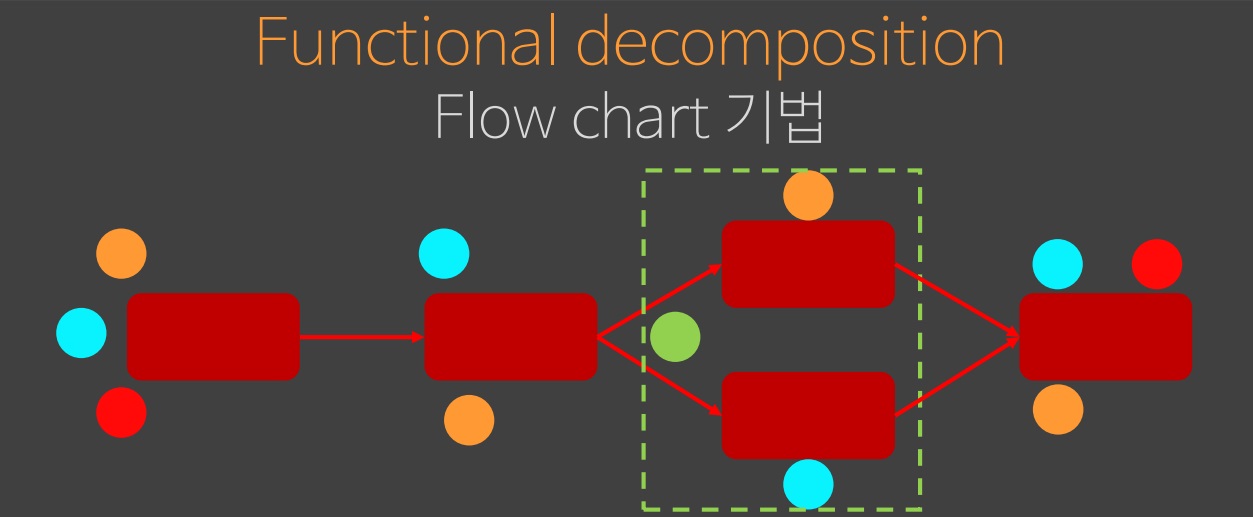
결국 제일 처음부터 빨간색을 선언하게 되고 결국 모든게 빨간색으로 된다.
2. Abstract Data Type (추상 데이터 타입)

이전까지 절차와 절차에 필요한 데이터를 깨닫는 과정이었지만 ADT(Abstract Data Type) 부터 데이터를 기준으로 판단한다. flow 시스템에서는 특정 동작에 해당 되는 데이터만 유추하기 때문에 마지막에 떠오르게 된지만 ADT(Abstract Data Type) 부터는 데이터에 따라 해야 될 동작들을 정리한다.

데이터의 차이점만 있고 flow 내부 동작의 공통점을 추상화의 단계에서 인식할 수 있다라면 위 그림과 같이 묶일 수 있다.
이 안에 if 문이나 switch 를 통해 case 상태를 수용한다면 코드 응집성이 높아져서 관리하기가 편해진다
도메인 지식을 모아 둘 수 있다는 것이 장점이지만 case 를 늘일때마다 코드의 양이 증가 된다.
바깥쪽에서는 하나의 형으로 인식하고 내부에서는 복잡한 로직을 감춰서 좋을 수 있다.

모든 종류의 상태를 수용하고 있으므로 내부에서 다 해결할 수 있다. 버그의 양도 적고, 코드도 짧고, 외부의 영향도 없고, 기능을 늘리기가 굉장히 쉽다.

하지만 새로운 유형의 데이터가 추가되면 전체 클래스가 파기되고 모든 메소드의 코드를 수정해야 한다. 이렇게 기능이 추가되거나 변화가 없다라면 장점 존재하기 때문에 이 책에서도 상태가 안정화 됐다면 ADT 도 나쁘지 않은 선택이라고 한다.

하지만 초록색 상태일 때만 해당되는 기능을 추가한다면 ADT 로는 해결할 수 없다. 즉, ADT는
- 상태가 확정되어야 한다.
- 모든 메소드가 가용한 상태 전체를 커버하는 메소드들로만 구성되어야 한다. 이 두가지를 만족해야 성립된다. ADT 를 사용할 수 있는 상황은 굉장히 제한적이다.
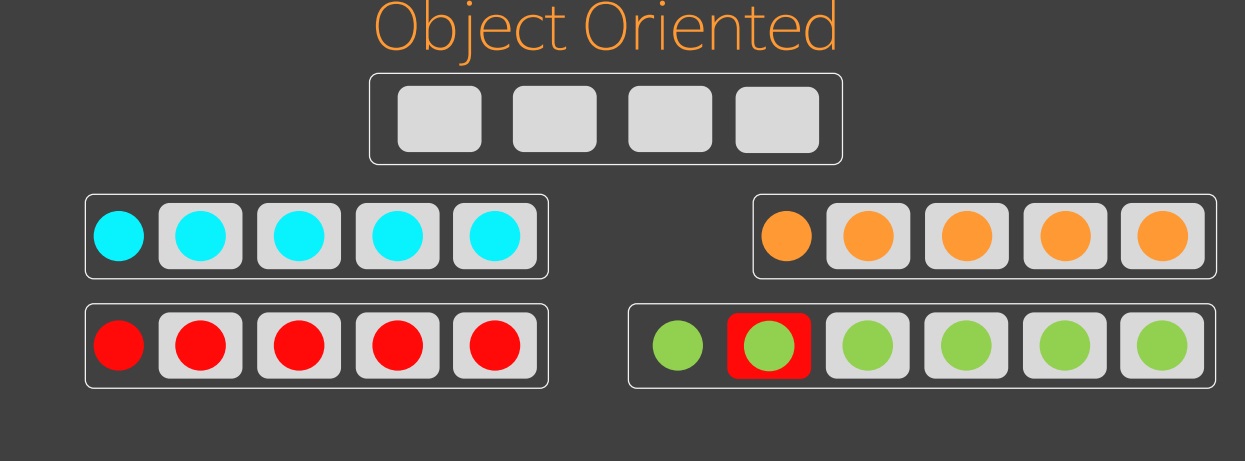
3. Object Oriented
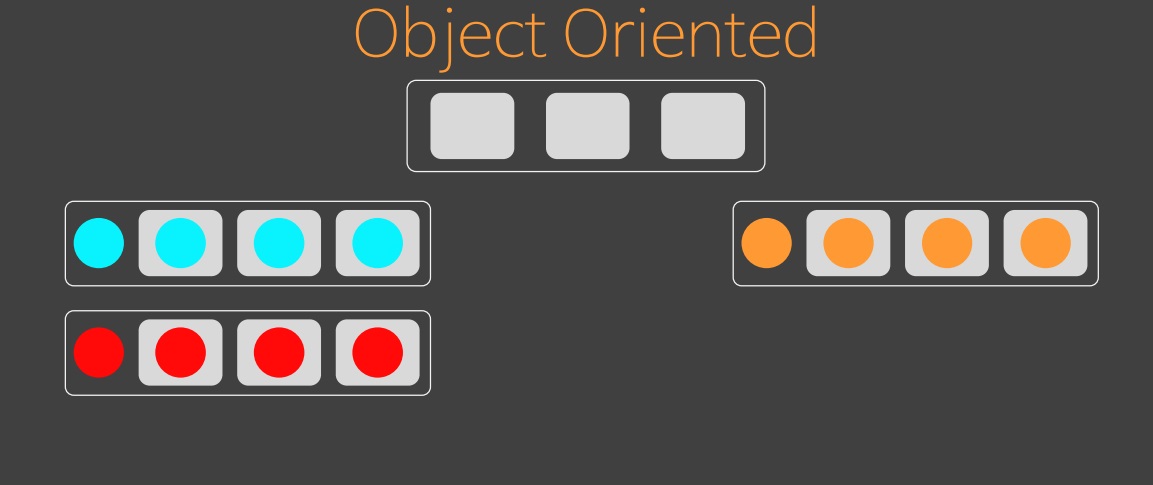
객체 지향의 사고방식에서는 상태가 없는 수준에서 추상화를 하고 상태에 따라 상속 구조를 변경하면서 형을 더 만든다. ADT 는 상태에 따라서 형을 줄어 들지만 객체 지향에서는 증가한다. 심지어, 상태 따라 생성된 형을 통합하는 추상형도 필요하다.
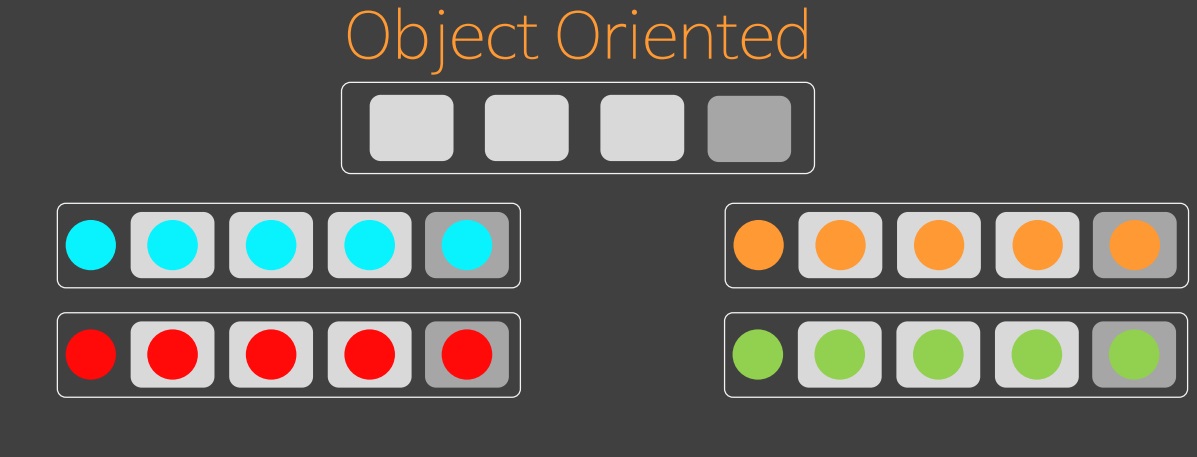
여파를 끼치지 않고 초록색에 필요한 코드만 만들 수 있게 됐다.
상태별로 if 문으로 관리하던 것에 비해, 지금은 상태만큼 객체의 클래스 형만 만들면 된다.
if 가 많으면 복잡성 폭발이 발생 되는데 이 복잡성 폭발을 제거하기 위해 oop 를 사용한다.
if 에 해당되는 case 만큼의 객체를 만들어서 client 쪽으로 if 를 밀어내는 것이 객체지향이다.
theater 에서 movie 는 원래 2단 if 였을 텐데 policy 를 소유하고 policy 가 condition 을 가지는 것으로 전략 객체로 바뀐것이다.
객체 지향은 상태가 추가될 때는 쉽지만 기능이 추가되면 다같이 변경된다. 그래서 객체 지향일 때 위험한 것이 성급한 추상화이다. 추상화가 제대로 되어 있지 않을 때, 상태를 늘리려고 하면 안된다.
이런 성급한 추상화를 피하는 방법은 추상화를 정규하게 만드는 동안에는 확인 할 수 있는 case 만 구상 클래스를 만드는 것이다. 그래서 kotlin 같은 경우, 상속 범위를 한정 짓고 구상 클래스의 범위를 제한하는 shield class 을 이용한다.
oop에서 초록색 상태에서만 필요한 메소드가 추가됐을 때,
추상 클래스로 인식하고 있다면 리스코프 치환원칙에 의해서 이 메소드를 사용할 수 있는 방법은 제한적이다.
언어마다 이 문제를 해결할 수 있는 방법은 존재겠지만 java 에서는 generic 을 이용하면 가능하다.
개발자의 세계 ADT
프로젝트가 진행되면서 자연스럽게 기능이 확장되거나 형이 확장되기 때문에 ADT 는 현실에서 거의 사용할 수 없다. 우리는 습관적으로 ADT 로 코드를 짜기 때문에 ADT 를 인식하기가 힘들다. 그래서 객체 지향과 ADT 의 차이점을 인식하기 위해 개발자의 세계를 ADT 버전으로 만든다.
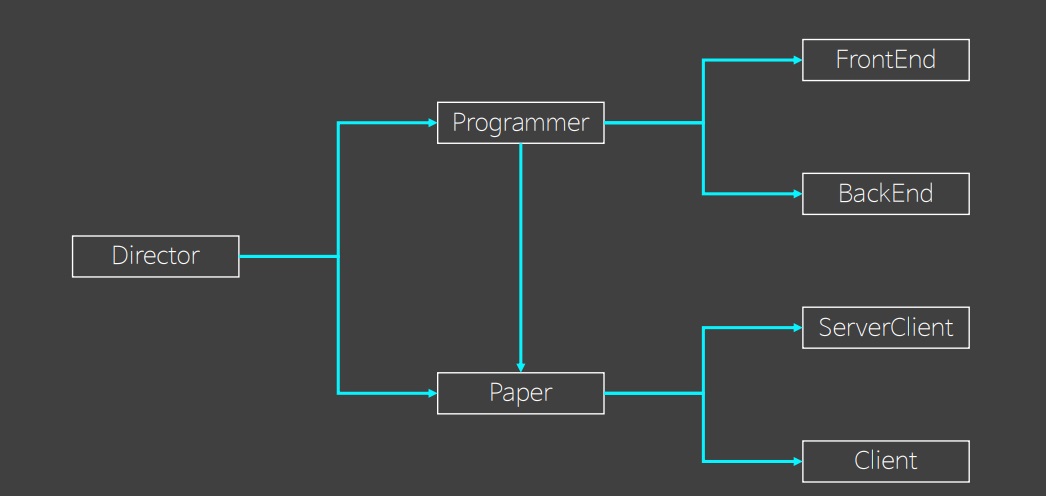
이전에 했던 개발자의 세계는 객체 지향을 통해 코드의 변화를 형으로 나누고 있다.
if 에 대한 case 만큼 형으로 치환하게 됐으므로 형이 증가하게 된다.
public interface Paper {}
public abstract class ServerClient implements Paper {
Server server = new Server("test");
Language backEndLanguage = new Language("java");
Language frontEndLanguage = new Language("kotlinJS");
private Programmer backEndProgrammer;
private Programmer frontEndProgrammer;
public void setBackEndProgrammer(Programmer programmer) {
this.backEndProgrammer = programmer;
}
public void setFrontEndProgrammer(Programmer programmer) {
this.frontEndProgrammer = programmer;
}
}
public abstract class Client implements Paper {
Library library = new Library("vueJS");
Language language = new Language("kotlinJS");
Programmer programmer;
public void setProgrammer(Programmer programmer) {
this.programmer = programmer;
}
}
전에 만들었던 Paper interface 를 확장해서 Client 와 ServerClient 를 만들었다.
이걸 ADT 로 합친다.
public class Paper {
public Paper(boolean isClient) {
this.isClient = isClient;
}
public final boolean isClient;
Library library = new Library("vueJS");
Language language = new Language("kotilinJS");
Programmer programmer;
Server server = new Server("test");
Language backEndLanguage = new Language("java");
Language frontEndLanguage = new Language("kotlinJS");
private Programmer backEndProgrammer;
private Programmer frontEndProgrammer;
public void setProgrammer(Programmer programmer) {
if (isClient) this.programmer = programmer;
}
public void setBackEndProgrammer(Programmer programmer) {
if (!isClient) this.backEndProgrammer = programmer;
}
public void setFrontEndProgrammer(Programmer programmer) {
if (!isClient) this.frontEndProgrammer = programmer;
}
}
Client 와 ServerClient 를 Paper 로 통합했다.
Paper interface 에 많은 method 가 있었다면 로직으로 통합했어야 하지만
interface에 method가 하나도 없었기 때문에 Client 와 ServerClient 전체를 복사해온다.
모든 상태를 소유할수 있도록 하고 flag 에 따라 분기를 나누게 된다.
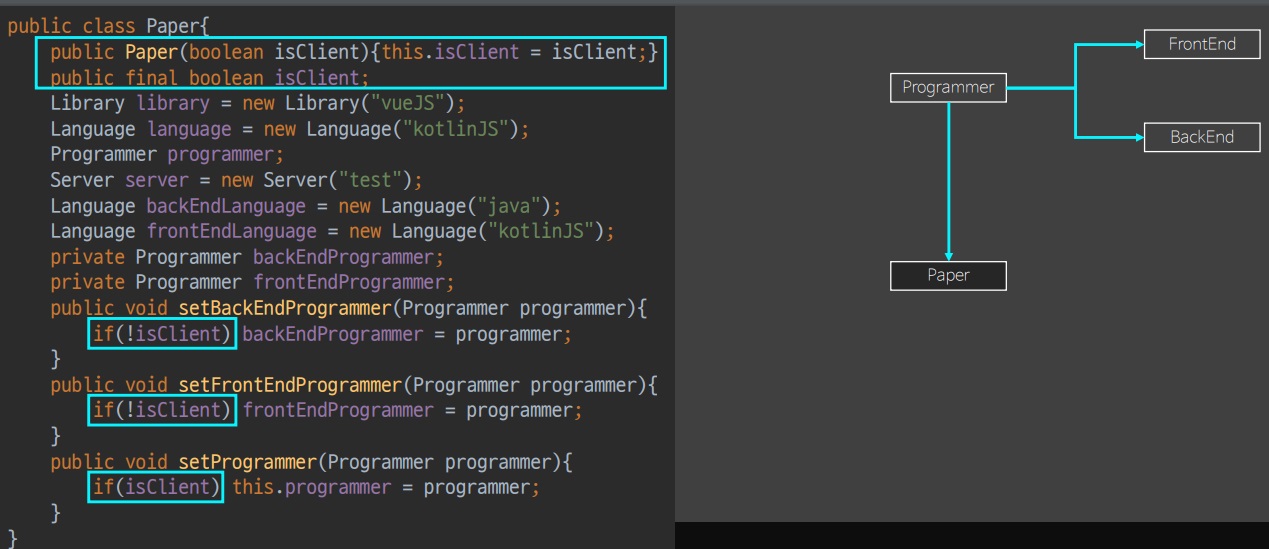
flag 변수에 대한 여파로 코드는 내부의 모든 상태를 커버할 수 있도록 변경해야 한다.
method 들은 모든 객체에 대해 동작 해야 하지만
코드를 보면 setBackEndProgrammer 와 setFrontEndProgrammer 는 ServerClient 일 때, setProgrammer 는 Client 일때만 작동한다.
암묵적으로 작동해야 할 상태가 정해져 있는게 ADT 의 문제이다.
public interface Programmer {
Program makeProgram(Paper paper);
}
public class FrontEnd implements Programmer {
private Language language;
private Library library;
@Override
public Program makeProgram(Paper paper) {
if (paper instanceof Client) {
Client pb = (Client) paper;
language = pb.language;
library = pb.library;
}
return makeFrontEndProgram();
}
private Program makeFrontEndProgram() {
return new Program();
}
}
public class BackEnd implements Programmer {
private Server server;
private Language language;
@Override
public Program makeProgram(Paper paper) {
if (paper instanceof ServerClient) {
ServerClient pa = (ServerClient) paper;
server = pa.server;
language = pa.backEndLanguage;
}
return makeFrontEndProgram();
}
private Program makeFrontEndProgram() {
return new Program();
}
}
Programmer에서 Paper 는 이제 하나로 통합되었기 때문에 FrontEnd, BackEnd 에서 instanceof 같은 코드는 제거 되었다.
이제 FrontEnd, BackEnd 도 Programmer 로 통합한다.
Paper 에서는 operation 이 없었지만 makeProgram 도 통합 해야 한다.
public class Programmer {
public Programmer(Boolean isFrontEnd) {
this.isFrontEnd = isFrontEnd;
}
public final boolean isFrontEnd;
private Language frontLanguage;
private Library frontLibrary;
private Server server;
private Language backEndLanguage;
public Program makeProgram(Paper paper) {
if (isFrontEnd) {
frontLanguage = paper.getFrontEndLanguage();
frontLibrary = paper.getFrontEndLibrary();
} else {
this.server = paper.getServer();
this.backEndLanguage = paper.getBackEndLanguage();
}
return isFrontEnd ? makeFrontEndProgram() : makeBackEndProgram();
}
private Program makeFrontEndProgram() {
return new Program();
}
private Program makeBackEndProgram() {
return new Program();
}
}
통합해보면 Programmer 는 isFrontEnd 를 통해 2가지 상태로 나눠진다.
원래 FrontEnd 와 BackEnd에는 같은 변수명 language이 있었는데 통합하면서 이름 충돌이 발생한다.
이름 충돌 해소를 위해 모든 부분을 수정한다.
통합하면서 language 라는 변수명은 이제 사용할 수 없고 frontEnd 와 backEnd 로 나눠서 사용해야 한다.
추상화 할 때, 추상화의 크기가 다르면 단계가 맞지 않아서 인식하기 힘들다.
그래서 추상화 layer 가 중요하다.
man 과 frontEnd 가 아닌 frontEnd 와 backEnd 로 해야 추상화 layer가 맞는 것이다.
위 코드에서 frontLanguage, backEndLanguage 라고 했는데 library 로 한다면 추상화 layer가 맞지 않는 것이다.
그래서 frontEndLibrary 로 바꿔줘야 한다.
ADT 는 시간순으로 상태가 추가될 때마다 이름 충돌로 인해 전부 나눠지게 되고 평소에 이름을 길게 짓게 되는 것이 문제다.
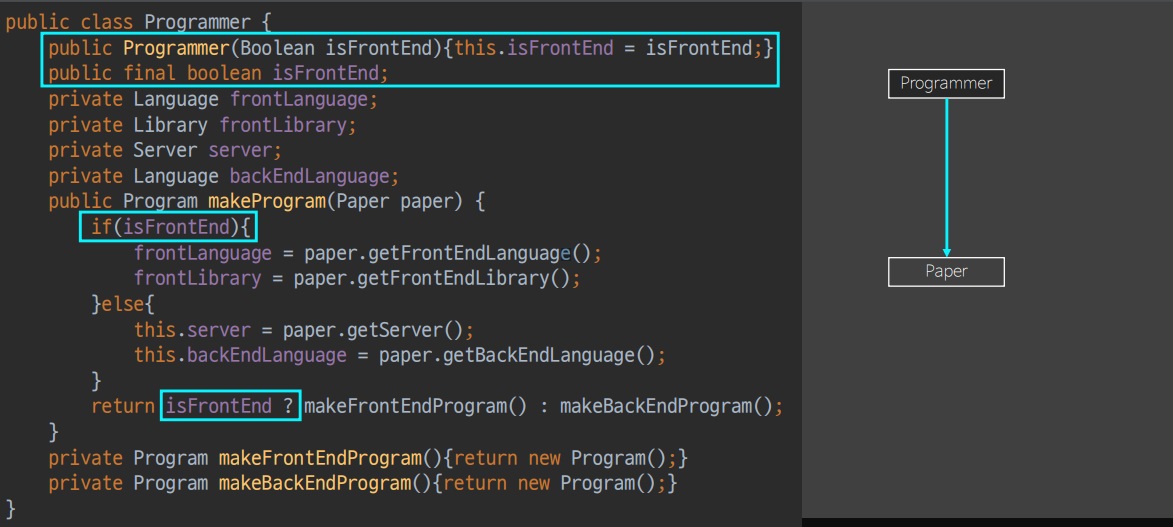
boolean 을 통해 모든 개발자를 통합한 추상형을 만들었다.
원래는 두개의 함수로 나눠져 있던게 이제는 if 를 통해서 하나의 함수로 모여져 지식의 통합이 발생했다.
모든 경우의 수가 보이게 되긴 했지만 문제가 생긴다.
frontLanguage 와 frontLibrary, server 와 backEndLanguage 모두 Paper를 통해서 정한다.
ADT 는 형끼리 결합할 수 없는 것이 두번째 문제이다.
본인 상태를 사용해서 분리하고 상태를 감추기 때문에 ADT 연쇄 로 인해 Paper 도 구분할 수 없으므로 통합 메소드를 통해 불러올 수 밖에 없다.
Paper 의 상태는 신경쓰지 않고 Programmer 상태가 frontEnd 라면 Paper 에게 frontEndLanguage 를 요청하는 getter 추상메소드를 만들게 된다.
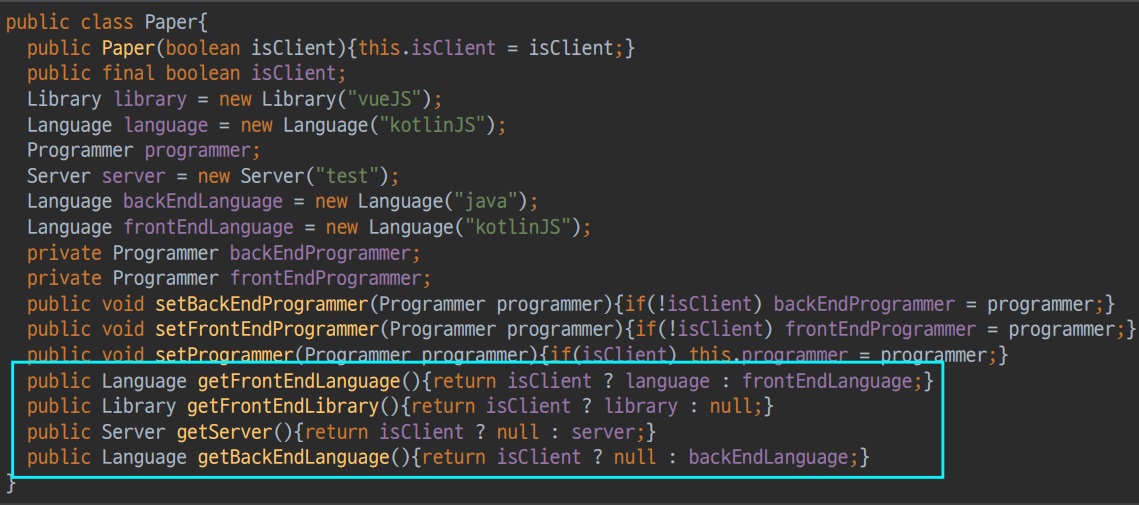
Paper 의 기능을 확장하면 위 코드와 같이 만들어진다.
method 들은 다시 isClient 에 따라 달라진다.
원래는 모든 상태를 커버하는 함수들이 만들어져야 하지만 server 와 client 에서 동작하는 코드가 구분된다.
그래서 형이 확정되고 변화가 없어도 ADT 를 사용하면 안된다.
작성한 method 가 비대칭으로 작동한다면 이미 ADT 로 짠 것이다.
public class Director {
private Map<String, Paper> projects = new HashMap<>();
public void addProject(String name, Paper paper){projects.put(name, paper);}
public void runProject(String name){
if(!projects.containsKey(name)) throw new RuntimeException("no project");
Paper paper = projects.get(name);
if(paper instanceof ServerClient){
ServerClient project = (ServerClient)paper;
Programmer frontEnd = new FrontEnd(), backEnd = new BackEnd();
project.setFrontEndProgrammer(frontEnd);
project.setBackEndProgrammer(backEnd);
Program client = frontEnd.makeProgram(project);
Program server = backEnd.makeProgram(project);
deploy(name, client, server);
}else if(paper instanceof Client){
Client project = (Client)paper;
Programmer frontEnd = new FrontEnd();
project.setProgrammer(frontEnd);
deploy(name, frontEnd.makeProgram(project));
}
}
private void deploy(String projectName, Program...programs){}
}
이전 Director 에서는 Paper 의 형에 따라서 동작이 다르다.
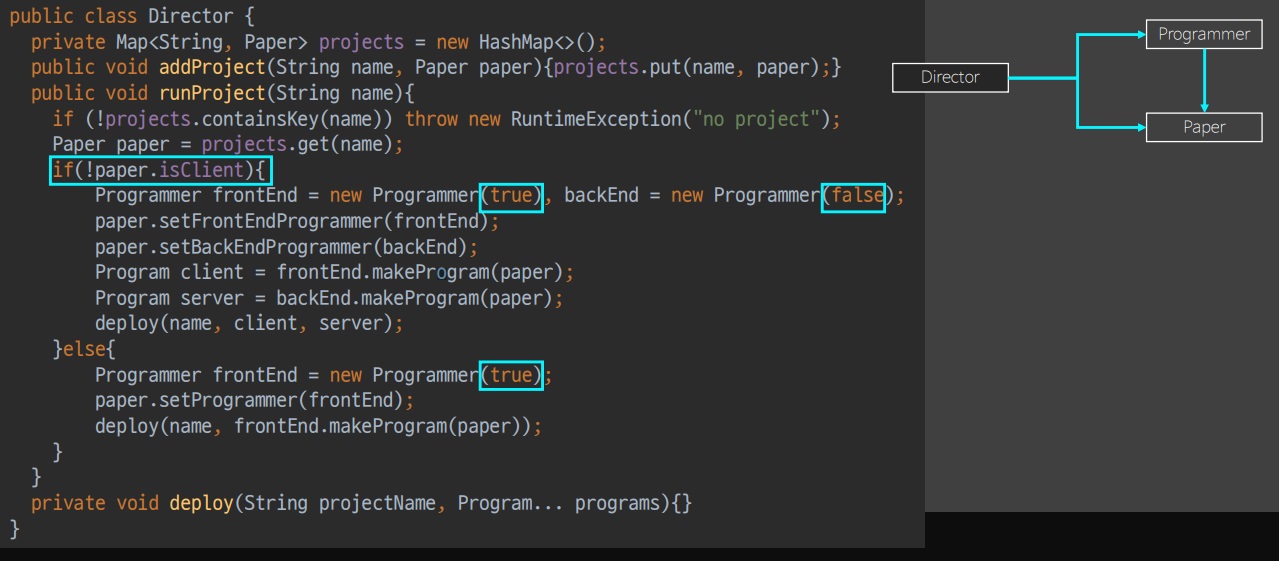
ADT 로 바꾸면 코드가 많이 달라지진 않지만 Director 에서 접근하려면 반드시 Paper 의 내부를 확인할 수 밖에 없다.
특정 Director 마다 이 코드가 달라질 수 있으므로 Paper 로 옮길 수도 없다.
Paper 의 상태를 노출하지 않고서는 경우에 따른 코드를 분리할 수가 없는 것이다.
그러면 ADT 의 진짜 목적이었던 내부형을 캡슐화하는 것도 어기게 된다.
내부에서 ADT 를 사용하면 추상화 되어 있을 것 같지만 ADT 를 활용해서 작동하는 setter 를 만들면 ADT 의 내부는 노출될 수 밖에 없다.
ADT 의 폐단
- 캡슐화 실패
- 데이터 은닉 실패
- context 가 일치하지 않는 getter 양산
- 본인의 상태 추상화 실패
결국, ADT 는 폐단이 많기 때문에 어떠한 경우에도 사용하면 안된다. 이 책에서는 기능이 안정화 됐다면 ADT 도 쓸만하다고 했지만 객체간 통신에 참여하는 순간 성립하지 않는다. oop 가 완화 시켜줄 순 있지만 ADT 끼리 있으면 단점은 더욱 심해진다. 결국엔 전부 oop 로 만들어야 한다.